Using Apache Phoenix
The Apache Phoenix project provides the ability to interact with HBase with JBDC using familiar SQL-syntax. The Phoenix dependencies are bundled with the Stackable HBase image and do not need to be installed separately (client components will need to ensure that they have the correct client-side libraries available). Information about client-side installation can be found here.
Phoenix comes bundled with a few simple scripts to verify a correct server-side installation. For example, assuming that phoenix dependencies have been installed to their default location of /stackable/phoenix/bin, we can issue the following using the supplied psql.py script:
/stackable/phoenix/bin/psql.py && \
/stackable/phoenix/examples/WEB_STAT.sql && \
/stackable/phoenix/examples/WEB_STAT.csv && \
/stackable/phoenix/examples/WEB_STAT_QUERIES.sqlThis script creates a java command that creates, populates and queries a Phoenix table called WEB_STAT. Alternatively, one can use the sqlline.py script (which wraps the sqlline utility):
/stackable/phoenix/bin/sqlline.py [zookeeper] [sql file]The script opens an SQL prompt from where one can list, query, create and generally interact with Phoenix tables. So, to query the table that was created in the previous step, start the script and enter some SQL at the prompt:
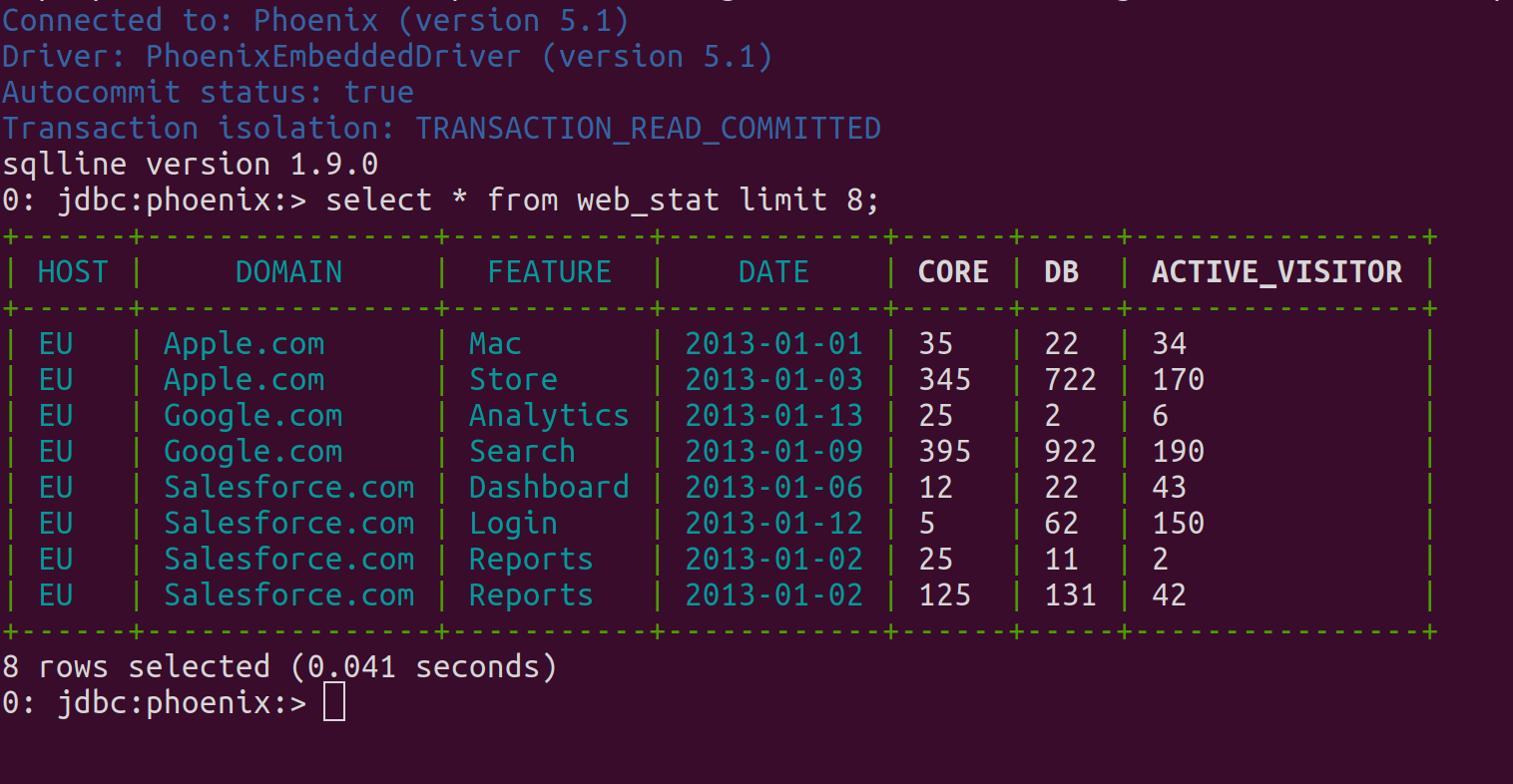
The Phoenix table WEB_STAT is created as an HBase table, and can be viewed normally from within the HBase UI:
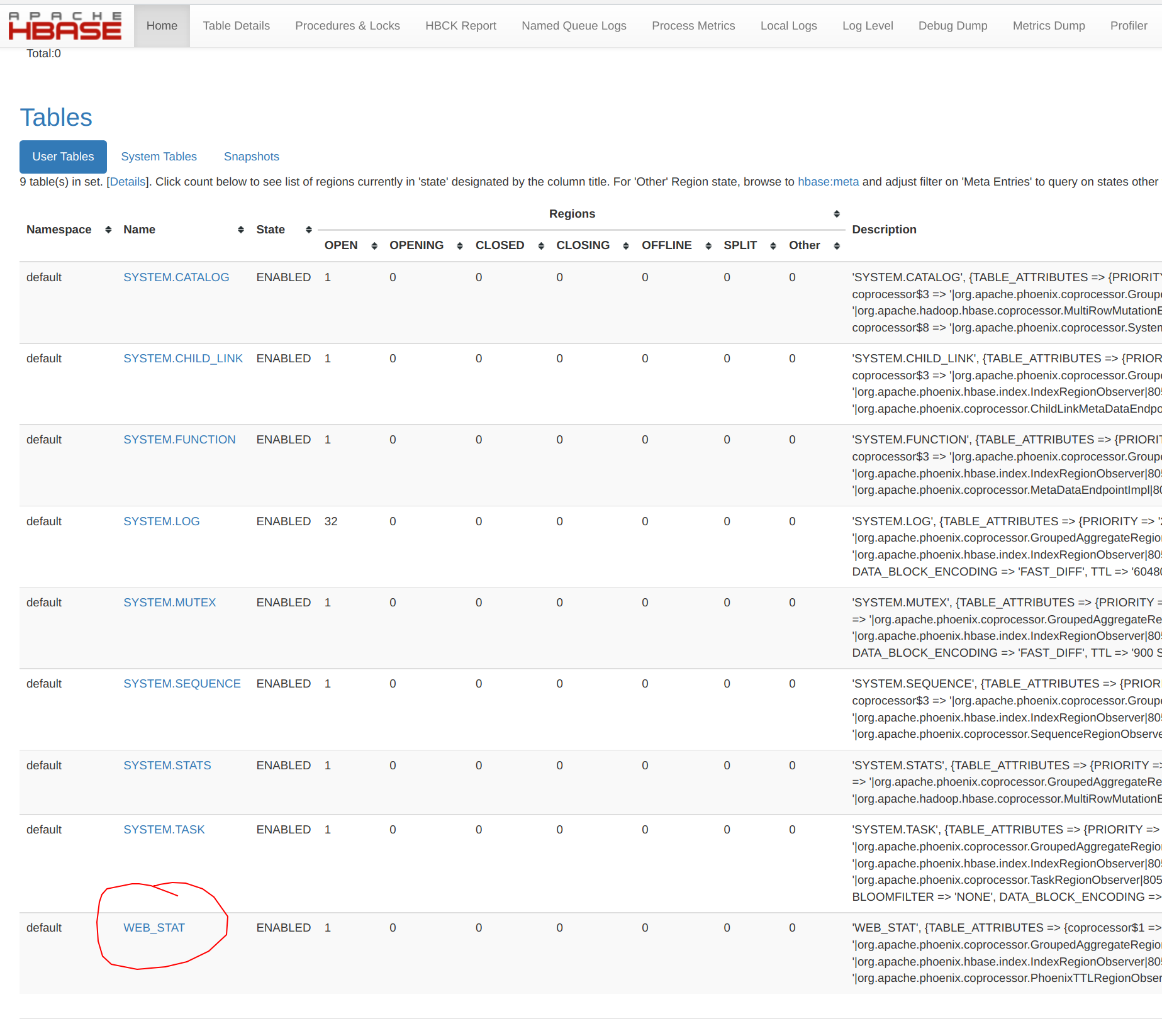
The SYSTEM* tables are those required by Phoenix and are created the first time that Phoenix is invoked.
Both psql.py and sqlline.py generate a java command that calls classes from the Phoenix client library .jar. The Zookeeper quorum does not need to be supplied as part of the URL used by the JDBC connection string, as long as the environment variable HBASE_CONF_DIR is set and supplied as an element for the -cp classpath search: the cluster information is then extracted from $HBASE_CONF_DIR/hbase-site.xml.
|