Usage
Monitoring
The managed Airflow instances are automatically configured to export Prometheus metrics. See Monitoring for more details.
Configuration & Environment Overrides
The cluster definition also supports overriding configuration properties and environment variables, either per role or per role group, where the more specific override (role group) has precedence over the less specific one (role).
| Overriding certain properties which are set by operator (such as the HTTP port) can interfere with the operator and can lead to problems. Additionally, for Airflow it is recommended that each component has the same configuration: not all components use each setting, but some things - such as external end-points - need to be consistent for things to work as expected. |
Configuration Properties
Airflow exposes an environment variable for every Airflow configuration setting, a list of which can be found in the Configuration Reference.
Although Kubernetes can override these settings in one of two ways (Configuration overrides, or Environment Variable overrides), the affect is the same and currently only the latter is implemented. This is described in the following section.
Environment Variables
These can be set - or overwritten - at either the role level:
webservers:
envOverrides:
AIRFLOW__WEBSERVER__AUTO_REFRESH_INTERVAL: "8"
roleGroups:
default:
replicas: 1Or per role group:
webservers:
roleGroups:
default:
envOverrides:
AIRFLOW__WEBSERVER__AUTO_REFRESH_INTERVAL: "8"
replicas: 1In both examples above we are replacing the default value of the UI DAG refresh (3s) with 8s. Note that all override property values must be strings.
Storage for data volumes
The Airflow Operator currently does not support using PersistentVolumeClaims for internal storage.
Resource Requests
Stackable operators handle resource requests in a sligtly different manner than Kubernetes. Resource requests are defined on role or group level. See Roles and role groups for details on these concepts. On a role level this means that e.g. all workers will use the same resource requests and limits. This can be further specified on role group level (which takes priority to the role level) to apply different resources.
This is an example on how to specify CPU and memory resources using the Stackable Custom Resources:
---
apiVersion: example.stackable.tech/v1alpha1
kind: ExampleCluster
metadata:
name: example
spec:
workers: # role-level
config:
resources:
cpu:
min: 300m
max: 600m
memory:
limit: 3Gi
roleGroups: # role-group-level
resources-from-role: # role-group 1
replicas: 1
resources-from-role-group: # role-group 2
replicas: 1
config:
resources:
cpu:
min: 400m
max: 800m
memory:
limit: 4GiIn this case, the role group resources-from-role will inherit the resources specified on the role level. Resulting in a maximum of 3Gi memory and 600m CPU resources.
The role group resources-from-role-group has maximum of 4Gi memory and 800m CPU resources (which overrides the role CPU resources).
| For Java products the actual used Heap memory is lower than the specified memory limit due to other processes in the Container requiring memory to run as well. Currently, 80% of the specified memory limits is passed to the JVM. |
For memory only a limit can be specified, which will be set as memory request and limit in the Container. This is to always guarantee a Container the full amount memory during Kubernetes scheduling.
If no resource requests are configured explicitely, the operator uses the following defaults:
workers:
roleGroups:
default:
config:
resources:
cpu:
min: '200m'
max: "4"
memory:
limit: '2Gi'Initializing the Airflow database
Airflow comes with a default embedded database (intended only for standalone mode): for cluster usage an external database is used such as PostgreSQL, described above. This database must be initialized with an airflow schema and the Admin user defined in the airflow credentials Secret. This is done the first time the cluster is created and can take a few moments.
Using Airflow
When the Airflow cluster is created and the database is initialized, Airflow can be opened in the browser.
The Airflow port which defaults to 8080 can be forwarded to the local host:
kubectl port-forward airflow-webserver-default-0 8080Then it can be opened in the browser with http://localhost:8080.
Enter the admin credentials from the Kubernetes secret:
If the examples were loaded then some dashboards are already available:
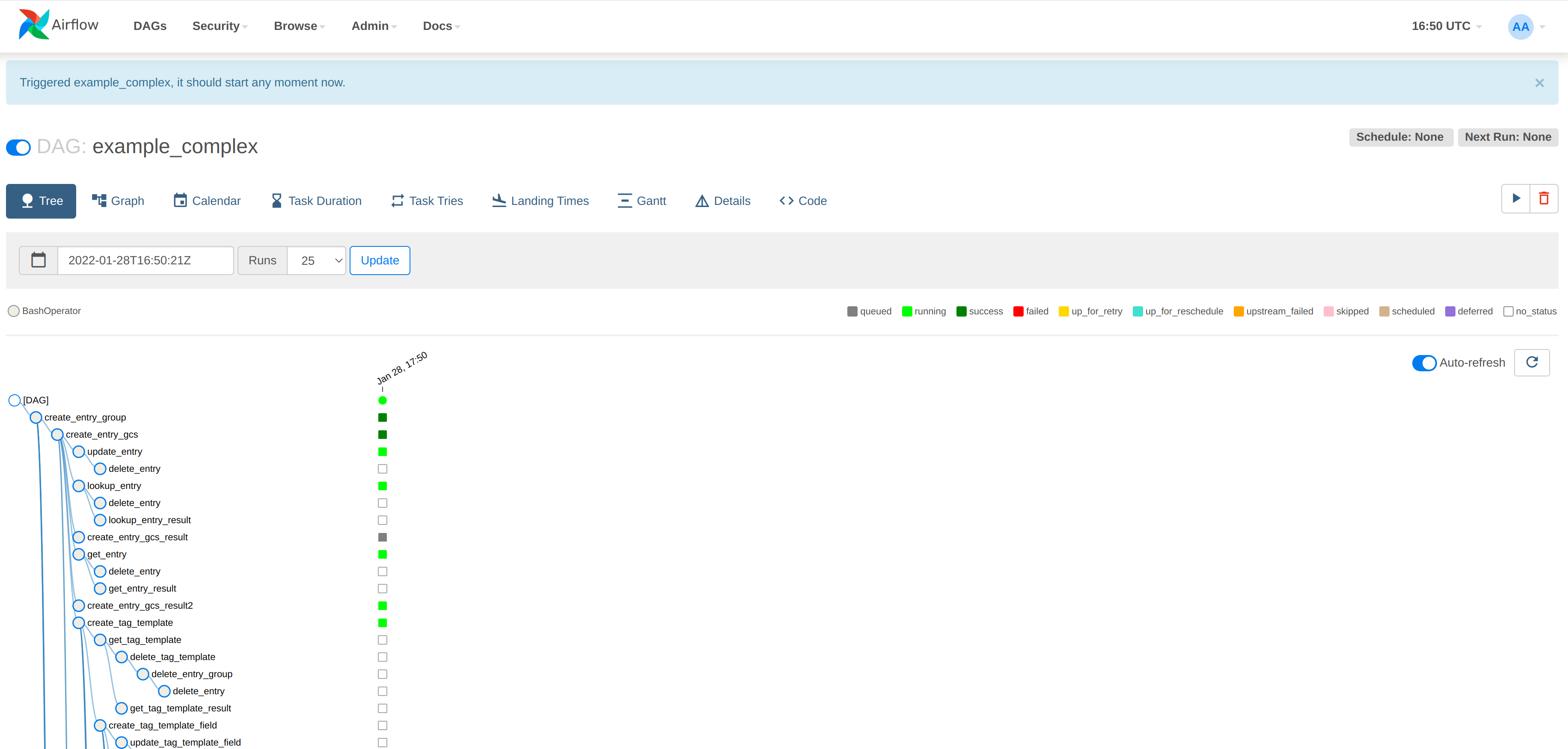
Click on an example DAG and then invoke the job: if the scheduler is correctly set up then the job will run and the job tree will update automatically:
Authentication
Every user has to authenticate themselves before using Airflow and there are several ways of doing this.
Webinterface
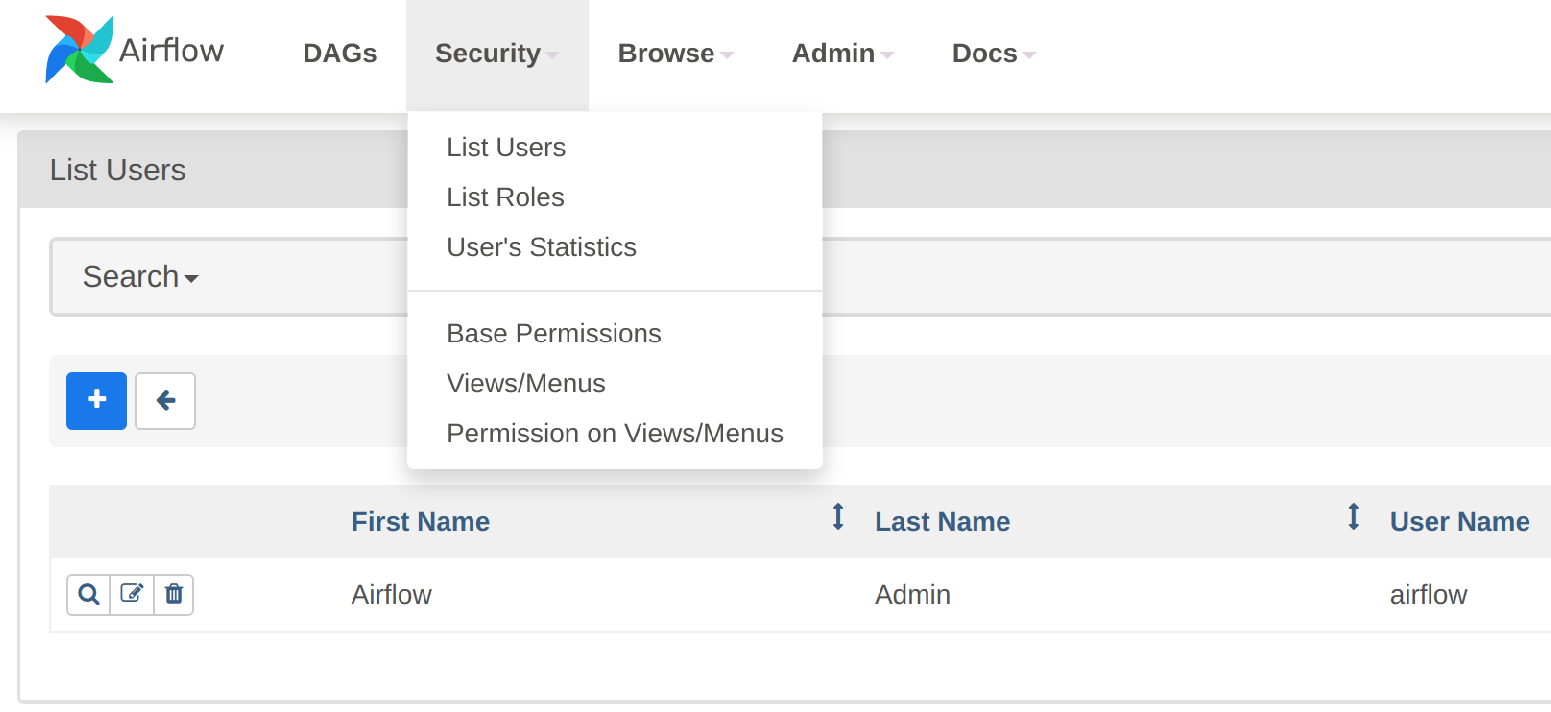
The default setting is to view and manually set up users via the Webserver UI. Note the blue "+" button where users can be added directly:
LDAP
Airflow supports authentication of users against an LDAP server. This requires setting up an AuthenticationClass for the LDAP server. The AuthenticationClass is then referenced in the AirflowCluster resource as follows:
apiVersion: airflow.stackable.tech/v1alpha1
kind: AirflowCluster
metadata:
name: airflow-with-ldap
spec:
image:
productVersion: 2.4.1
stackableVersion: 0.7.0
[...]
authenticationConfig:
authenticationClass: ldap (1)
userRegistrationRole: Admin (2)| 1 | The reference to an AuthenticationClass called ldap |
| 2 | The default role that all users are assigned to |
Users that log in with LDAP are assigned to a default Role which is specified with the userRegistrationRole property.
You can follow the Authentication with OpenLDAP tutorial to learn how to set up an AuthenticationClass for an LDAP server, as well as consulting the AuthenticationClass reference.
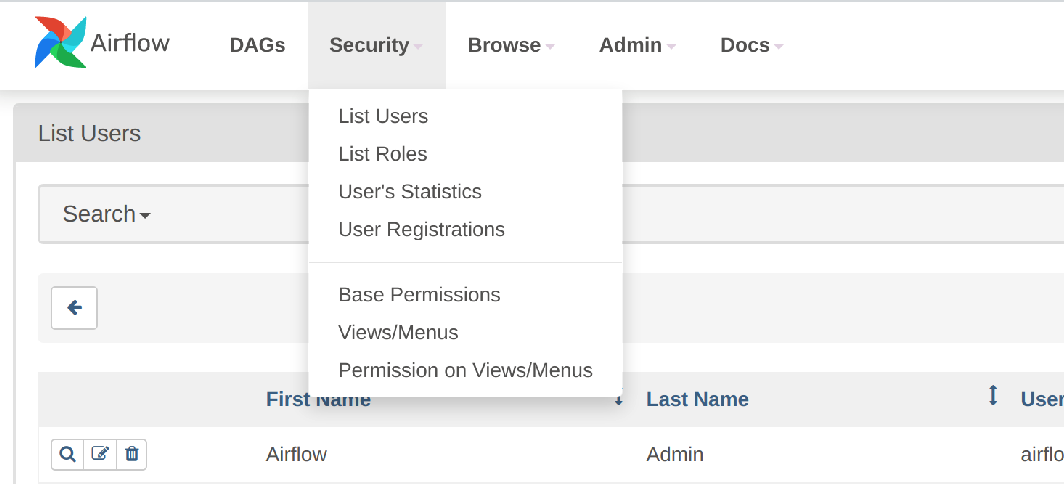
The users and roles can be viewed as before in the Webserver UI, but note that the blue "+" button is not available when authenticating against LDAP:
Authorization
The Airflow Webserver delegates the handling of user access control to Flask AppBuilder.
Webinterface
You can view, add to, and assign the roles displayed in the Airflow Webserver UI to existing users.
LDAP
Airflow supports assigning Roles to users based on their LDAP group membership, though this is not yet supported by the Stackable operator.
All the users logging in via LDAP get assigned to the same role which you can configure via the attribute authenticationConfig.userRegistrationRole on the AirflowCluster object:
apiVersion: airflow.stackable.tech/v1alpha1
kind: AirflowCluster
metadata:
name: airflow-with-ldap
spec:
[...]
authenticationConfig:
authenticationClass: ldap
userRegistrationRole: Admin (1)| 1 | All users are assigned to the Admin role |
Monitoring
The managed Airflow instances are automatically configured to export Prometheus metrics. See Monitoring for more details
Mounting DAGs
DAGs can be mounted by using a ConfigMap or a PersistentVolumeClaim. This is best illustrated with an example of each, shown in the next section.
via ConfigMap
---
apiVersion: v1
kind: ConfigMap
metadata:
name: cm-dag (1)
data:
test_airflow_dag.py: | (2)
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.dummy import DummyOperator
with DAG(
dag_id='test_airflow_dag',
schedule_interval='0 0 * * *',
start_date=datetime(2021, 1, 1),
catchup=False,
dagrun_timeout=timedelta(minutes=60),
tags=['example', 'example2'],
params={"example_key": "example_value"},
) as dag:
run_this_last = DummyOperator(
task_id='run_this_last',
)
# [START howto_operator_bash]
run_this = BashOperator(
task_id='run_after_loop',
bash_command='echo 1',
)
# [END howto_operator_bash]
run_this >> run_this_last
for i in range(3):
task = BashOperator(
task_id='runme_' + str(i),
bash_command='echo "{{ task_instance_key_str }}" && sleep 1',
)
task >> run_this
# [START howto_operator_bash_template]
also_run_this = BashOperator(
task_id='also_run_this',
bash_command='echo "run_id={{ run_id }} | dag_run={{ dag_run }}"',
)
# [END howto_operator_bash_template]
also_run_this >> run_this_last
# [START howto_operator_bash_skip]
this_will_skip = BashOperator(
task_id='this_will_skip',
bash_command='echo "hello world"; exit 99;',
dag=dag,
)
# [END howto_operator_bash_skip]
this_will_skip >> run_this_last
if __name__ == "__main__":
dag.cli()---
apiVersion: airflow.stackable.tech/v1alpha1
kind: AirflowCluster
metadata:
name: airflow
spec:
image:
productVersion: 2.4.1
stackableVersion: 0.7.0
executor: CeleryExecutor
loadExamples: false
exposeConfig: false
credentialsSecret: simple-airflow-credentials
volumes:
- name: cm-dag (3)
configMap:
name: cm-dag (4)
volumeMounts:
- name: cm-dag (5)
mountPath: /dags/test_airflow_dag.py (6)
subPath: test_airflow_dag.py (7)
webservers:
roleGroups:
default:
envOverrides:
AIRFLOW__CORE__DAGS_FOLDER: "/dags" (8)
replicas: 1
workers:
roleGroups:
default:
envOverrides:
AIRFLOW__CORE__DAGS_FOLDER: "/dags" (8)
replicas: 2
schedulers:
roleGroups:
default:
envOverrides:
AIRFLOW__CORE__DAGS_FOLDER: "/dags" (8)
replicas: 1
| 1 | The name of the configuration map |
| 2 | The name of the DAG (this is a renamed copy of the example_bash_operator.py from the Airflow examples) |
| 3 | The volume backed by the configuration map |
| 4 | The name of the configuration map referenced by the Airflow cluster |
| 5 | The name of the mounted volume |
| 6 | The path of the mounted resource. Note that should map to a single DAG. |
| 7 | The resource has to be defined using subPath: this is to prevent the versioning of configuration map elements which may cause a conflict with how Airflow propagates DAGs between its components. |
| 8 | If the mount path described above is anything other than the standard location (the default is $AIRFLOW_HOME/dags), then the location should be defined using the relevant environment variable. |
The advantage of this approach is that a DAG can be provided "in-line", as it were. This becomes cumbersome when multiple DAGs are to be made available in this way, as each one has to be mapped individually. For multiple DAGs it is probably easier to expose them all via a mounted volume, which is shown below.
via PersistentVolumeclaim
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-airflow (1)
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: batch/v1
kind: Job (2)
metadata:
name: airflow-dags
spec:
template:
spec:
restartPolicy: Never
volumes:
- name: external-dags (3)
persistentVolumeClaim:
claimName: pvc-airflow (4)
initContainers:
- name: dest-dir
image: docker.stackable.tech/stackable/tools:0.2.0-stackable0.4.0
env:
- name: DEST_DIR
value: "/stackable/externals"
command:
[
"bash",
"-x",
"-c",
"mkdir -p $DEST_DIR && chown stackable:stackable ${DEST_DIR} && chmod -R a=,u=rwX,g=rwX ${DEST_DIR}",
]
securityContext:
runAsUser: 0
volumeMounts:
- name: external-dags (5)
mountPath: /stackable/externals (6)
containers:
- name: airflow-dags
image: docker.stackable.tech/stackable/tools:0.2.0-stackable0.4.0
env:
- name: DEST_DIR
value: "/stackable/externals"
command: (7)
[
"bash",
"-x",
"-c",
"curl -L https://raw.githubusercontent.com/apache/airflow/2.4.1/airflow/example_dags/example_bash_operator.py \
-o ${DEST_DIR}/example_bash_operator.py && \
curl -L https://raw.githubusercontent.com/apache/airflow/2.4.1/airflow/example_dags/example_complex.py \
-o ${DEST_DIR}/example_complex.py && \
curl -L https://raw.githubusercontent.com/apache/airflow/2.4.1/airflow/example_dags/example_branch_datetime_operator.py \
-o ${DEST_DIR}/example_branch_datetime_operator.py",
]
volumeMounts:
- name: external-dags (5)
mountPath: /stackable/externals (6)---
apiVersion: airflow.stackable.tech/v1alpha1
kind: AirflowCluster
metadata:
name: airflow
spec:
image:
productVersion: 2.4.1
stackableVersion: 0.7.0
executor: CeleryExecutor
loadExamples: false
exposeConfig: false
credentialsSecret: simple-airflow-credentials
volumes:
- name: external-dags (8)
persistentVolumeClaim:
claimName: pvc-airflow (9)
volumeMounts:
- name: external-dags (10)
mountPath: /stackable/external-dags (11)
webservers:
roleGroups:
default:
envOverrides:
AIRFLOW__CORE__DAGS_FOLDER: "/stackable/external-dags" (12)
replicas: 1
workers:
roleGroups:
default:
envOverrides:
AIRFLOW__CORE__DAGS_FOLDER: "/stackable/external-dags" (12)
replicas: 2
schedulers:
roleGroups:
default:
envOverrides:
AIRFLOW__CORE__DAGS_FOLDER: "/stackable/external-dags" (12)
replicas: 1| 1 | The name of the PersistentVolumeClaim that references the PV |
| 2 | Job used to populate the PersistentVolumeClaim with DAG files |
| 3 | The volume name that will be mounted as a target for the DAG files |
| 4 | Defines the Volume backed by the PVC, local to the Custom Resource |
| 5 | The VolumeMount used by the Custom Resource |
| 6 | The path for the VolumeMount |
| 7 | The command used to access/download the DAG files to a specified location |
| 8 | The Volume used by this Custom Resource |
| 9 | The PersistentVolumeClaim that backs this Volume |
| 10 | The VolumeMount referencing the Volume in the previous step |
| 11 | The path where this Volume is located for each role (webserver, worker, scheduler) |
| 12 | If the mount path described above is anything other than the standard location (the default is $AIRFLOW_HOME/dags), then the location should be defined using the relevant environment variable. |
Node selection
Airflow expects that all its components (webserver, scheduler, workers etc.) have access to the DAG folder. If this is mounted via a PersistentVolumeClaim, then the permissible access modes on that claim may require that a specific node is selected. This can be done by providing a label-match as shown below:
workers:
roleGroups:
default:
envOverrides:
AIRFLOW__CORE__DAGS_FOLDER: "/stackable/external-dags"
replicas: 1
selector:
matchLabels:
node: "2"Applying Custom Resources
Airflow can be used to apply custom resources from within a cluster. An example of this could be a SparkApplication job that is to be triggered by Airflow. The steps below describe how this can be done.
Define an in-cluster Kubernetes connection
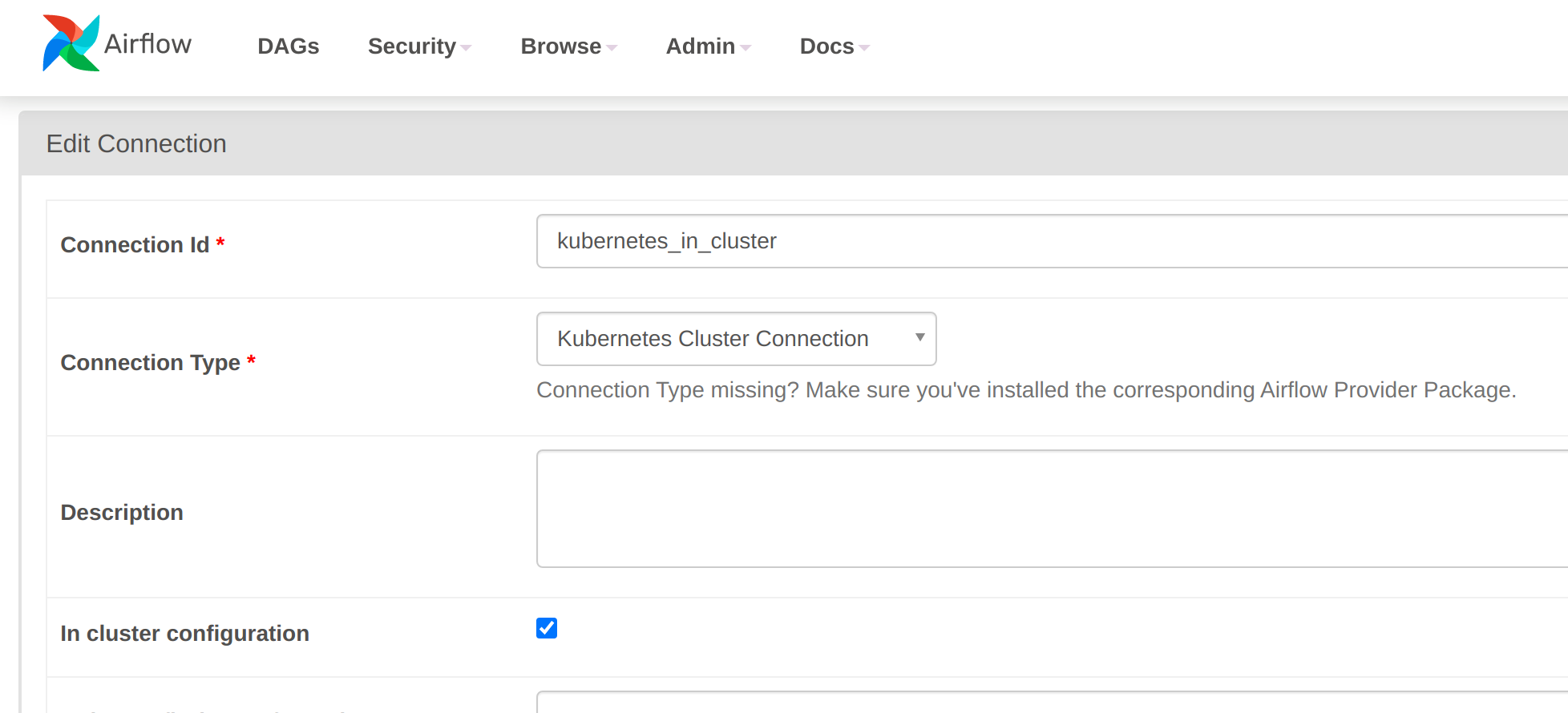
An in-cluster connection can either be created from within the Webserver UI (note that the "in cluster configuration" box is ticked):
Alternatively, the connection can be defined by an environment variable in URI format:
AIRFLOW_CONN_KUBERNETES_IN_CLUSTER: "kubernetes://?__extra__=%7B%22extra__kubernetes__in_cluster%22%3A+true%2C+%22extra__kubernetes__kube_config%22%3A+%22%22%2C+%22extra__kubernetes__kube_config_path%22%3A+%22%22%2C+%22extra__kubernetes__namespace%22%3A+%22%22%7D"This can be supplied directly in the custom resource for all roles (Airflow expects configuration to be common across components):
---
apiVersion: airflow.stackable.tech/v1alpha1
kind: AirflowCluster
metadata:
name: airflow
spec:
image:
productVersion: 2.4.1
stackableVersion: 0.7.0
executor: CeleryExecutor
loadExamples: false
exposeConfig: false
credentialsSecret: simple-airflow-credentials
webservers:
roleGroups:
default:
envOverrides:
AIRFLOW_CONN_KUBERNETES_IN_CLUSTER: "kubernetes://?__extra__=%7B%22extra__kubernetes__in_cluster%22%3A+true%2C+%22extra__kubernetes__kube_config%22%3A+%22%22%2C+%22extra__kubernetes__kube_config_path%22%3A+%22%22%2C+%22extra__kubernetes__namespace%22%3A+%22%22%7D"
replicas: 1
workers:
roleGroups:
default:
envOverrides:
AIRFLOW_CONN_KUBERNETES_IN_CLUSTER: "kubernetes://?__extra__=%7B%22extra__kubernetes__in_cluster%22%3A+true%2C+%22extra__kubernetes__kube_config%22%3A+%22%22%2C+%22extra__kubernetes__kube_config_path%22%3A+%22%22%2C+%22extra__kubernetes__namespace%22%3A+%22%22%7D"
replicas: 1
schedulers:
roleGroups:
default:
envOverrides:
AIRFLOW_CONN_KUBERNETES_IN_CLUSTER: "kubernetes://?__extra__=%7B%22extra__kubernetes__in_cluster%22%3A+true%2C+%22extra__kubernetes__kube_config%22%3A+%22%22%2C+%22extra__kubernetes__kube_config_path%22%3A+%22%22%2C+%22extra__kubernetes__namespace%22%3A+%22%22%7D"
replicas: 1Define a cluster role for Airflow to create SparkApplication resources
Airflow cannot create or access SparkApplication resources by default - a cluster role is required for this:
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: airflow-spark-clusterrole
rules:
- apiGroups:
- spark.stackable.tech
resources:
- sparkapplications
verbs:
- create
- getand a corresponding cluster role binding:
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: airflow-spark-clusterrole-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: airflow-spark-clusterrole
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:serviceaccountsDAG code
Now for the DAG itself. The job to be started is a simple Spark job that calculates the value of pi:
---
apiVersion: spark.stackable.tech/v1alpha1
kind: SparkApplication
metadata:
name: pyspark-pi
namespace: default
spec:
version: "1.0"
sparkImage: docker.stackable.tech/stackable/pyspark-k8s:3.3.0-stackable0.3.0
mode: cluster
mainApplicationFile: local:///stackable/spark/examples/src/main/python/pi.py
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
executor:
cores: 1
instances: 3
memory: "512m"This will called from within a DAG by using the connection that was defined earlier. It will be wrapped by the KubernetesHook that the Airflow Kubernetes provider makes available. There are two classes that are used to:
-
start the job
-
monitor the status of the job
These are written in-line in the python code below, though this is just to make it clear how the code is used (the classes SparkKubernetesOperator and SparkKubernetesSensor will be used for all custom resources and thus are best defined as separate python files that the DAG would reference).
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
"""Example DAG demonstrating how to apply a Kubernetes Resource from Airflow running in-cluster"""
from datetime import datetime, timedelta
from airflow import DAG
from typing import TYPE_CHECKING, Optional, Sequence, Dict
from kubernetes import client
from airflow.exceptions import AirflowException
from airflow.sensors.base import BaseSensorOperator
from airflow.models import BaseOperator
from airflow.providers.cncf.kubernetes.hooks.kubernetes import KubernetesHook
if TYPE_CHECKING:
from airflow.utils.context import Context
class SparkKubernetesOperator(BaseOperator): (1)
"""
Creates a SparkApplication resource in kubernetes:
:param application_file: Defines a 'SparkApplication' custom resource as either a
path to a '.yaml' file, '.json' file, YAML string or JSON string.
:param namespace: kubernetes namespace for the SparkApplication
:param kubernetes_conn_id: The :ref:`kubernetes connection id <howto/connection:kubernetes>`
for the Kubernetes cluster.
:param api_group: SparkApplication API group
:param api_version: SparkApplication API version
"""
template_fields: Sequence[str] = ('application_file', 'namespace')
template_ext: Sequence[str] = ('.yaml', '.yml', '.json')
ui_color = '#f4a460'
def __init__(
self,
*,
application_file: str,
namespace: Optional[str] = None,
kubernetes_conn_id: str = 'kubernetes_in_cluster', (2)
api_group: str = 'spark.stackable.tech',
api_version: str = 'v1alpha1',
**kwargs,
) -> None:
super().__init__(**kwargs)
self.application_file = application_file
self.namespace = namespace
self.kubernetes_conn_id = kubernetes_conn_id
self.api_group = api_group
self.api_version = api_version
self.plural = "sparkapplications"
def execute(self, context: 'Context'):
hook = KubernetesHook(conn_id=self.kubernetes_conn_id)
self.log.info("Creating SparkApplication...")
response = hook.create_custom_object(
group=self.api_group,
version=self.api_version,
plural=self.plural,
body=self.application_file,
namespace=self.namespace,
)
return response
class SparkKubernetesSensor(BaseSensorOperator): (3)
"""
Monitors a SparkApplication resource in kubernetes:
:param application_name: SparkApplication resource name
:param namespace: the kubernetes namespace where the SparkApplication reside in
:param kubernetes_conn_id: The :ref:`kubernetes connection<howto/connection:kubernetes>`
to Kubernetes cluster.
:param attach_log: determines whether logs for driver pod should be appended to the sensor log
:param api_group: SparkApplication API group
:param api_version: SparkApplication API version
"""
template_fields = ("application_name", "namespace")
FAILURE_STATES = ("Failed", "Unknown")
SUCCESS_STATES = ("Succeeded")
def __init__(
self,
*,
application_name: str,
attach_log: bool = False,
namespace: Optional[str] = None,
kubernetes_conn_id: str = 'kubernetes_in_cluster', (2)
api_group: str = 'spark.stackable.tech',
api_version: str = 'v1alpha1',
poke_interval: float = 60,
**kwargs,
) -> None:
super().__init__(**kwargs)
self.application_name = application_name
self.attach_log = attach_log
self.namespace = namespace
self.kubernetes_conn_id = kubernetes_conn_id
self.hook = KubernetesHook(conn_id=self.kubernetes_conn_id)
self.api_group = api_group
self.api_version = api_version
self.poke_interval = poke_interval
def _log_driver(self, application_state: str, response: dict) -> None:
if not self.attach_log:
return
status_info = response["status"]
if "driverInfo" not in status_info:
return
driver_info = status_info["driverInfo"]
if "podName" not in driver_info:
return
driver_pod_name = driver_info["podName"]
namespace = response["metadata"]["namespace"]
log_method = self.log.error if application_state in self.FAILURE_STATES else self.log.info
try:
log = ""
for line in self.hook.get_pod_logs(driver_pod_name, namespace=namespace):
log += line.decode()
log_method(log)
except client.rest.ApiException as e:
self.log.warning(
"Could not read logs for pod %s. It may have been disposed.\n"
"Make sure timeToLiveSeconds is set on your SparkApplication spec.\n"
"underlying exception: %s",
driver_pod_name,
e,
)
def poke(self, context: Dict) -> bool:
self.log.info("Poking: %s", self.application_name)
response = self.hook.get_custom_object(
group=self.api_group,
version=self.api_version,
plural="sparkapplications",
name=self.application_name,
namespace=self.namespace,
)
try:
application_state = response["status"]["phase"]
except KeyError:
self.log.debug(f"SparkApplication status could not be established: {response}")
return False
if self.attach_log and application_state in self.FAILURE_STATES + self.SUCCESS_STATES:
self._log_driver(application_state, response)
if application_state in self.FAILURE_STATES:
raise AirflowException(f"SparkApplication failed with state: {application_state}")
elif application_state in self.SUCCESS_STATES:
self.log.info("SparkApplication ended successfully")
return True
else:
self.log.info("SparkApplication is still in state: %s", application_state)
return False
with DAG( (4)
dag_id='sparkapp_dag',
schedule_interval='0 0 * * *',
start_date=datetime(2021, 1, 1),
catchup=False,
dagrun_timeout=timedelta(minutes=60),
tags=['example'],
params={"example_key": "example_value"},
) as dag:
t1 = SparkKubernetesOperator( (5)
task_id='spark_pi_submit',
namespace="default",
application_file="pyspark-pi.yaml",
do_xcom_push=True,
dag=dag,
)
t2 = SparkKubernetesSensor( (6)
task_id='spark_pi_monitor',
namespace="default",
application_name="{{ task_instance.xcom_pull(task_ids='spark_pi_submit')['metadata']['name'] }}",
poke_interval=5,
dag=dag,
)
t1 >> t2 (7)| 1 | the wrapper class used for calling the job via KubernetesHook |
| 2 | the connection that created for in-cluster usage |
| 3 | the wrapper class used for monitoring the job via KubernetesHook |
| 4 | the start of the DAG code |
| 5 | the initial task to invoke the job |
| 6 | the subsequent task to monitor the job |
| 7 | the jobs are chained together in the correct order |
Once this DAG is mounted in the DAG folder it can be called and its progress viewed from within the Webserver UI:
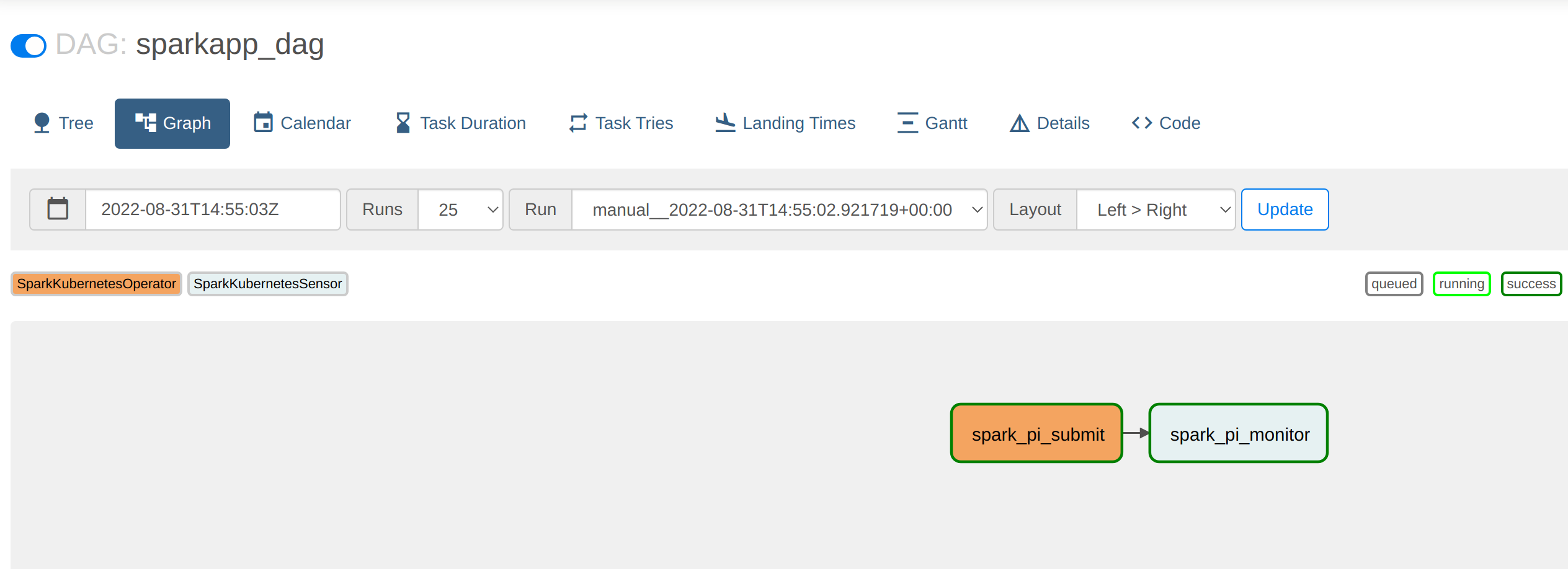
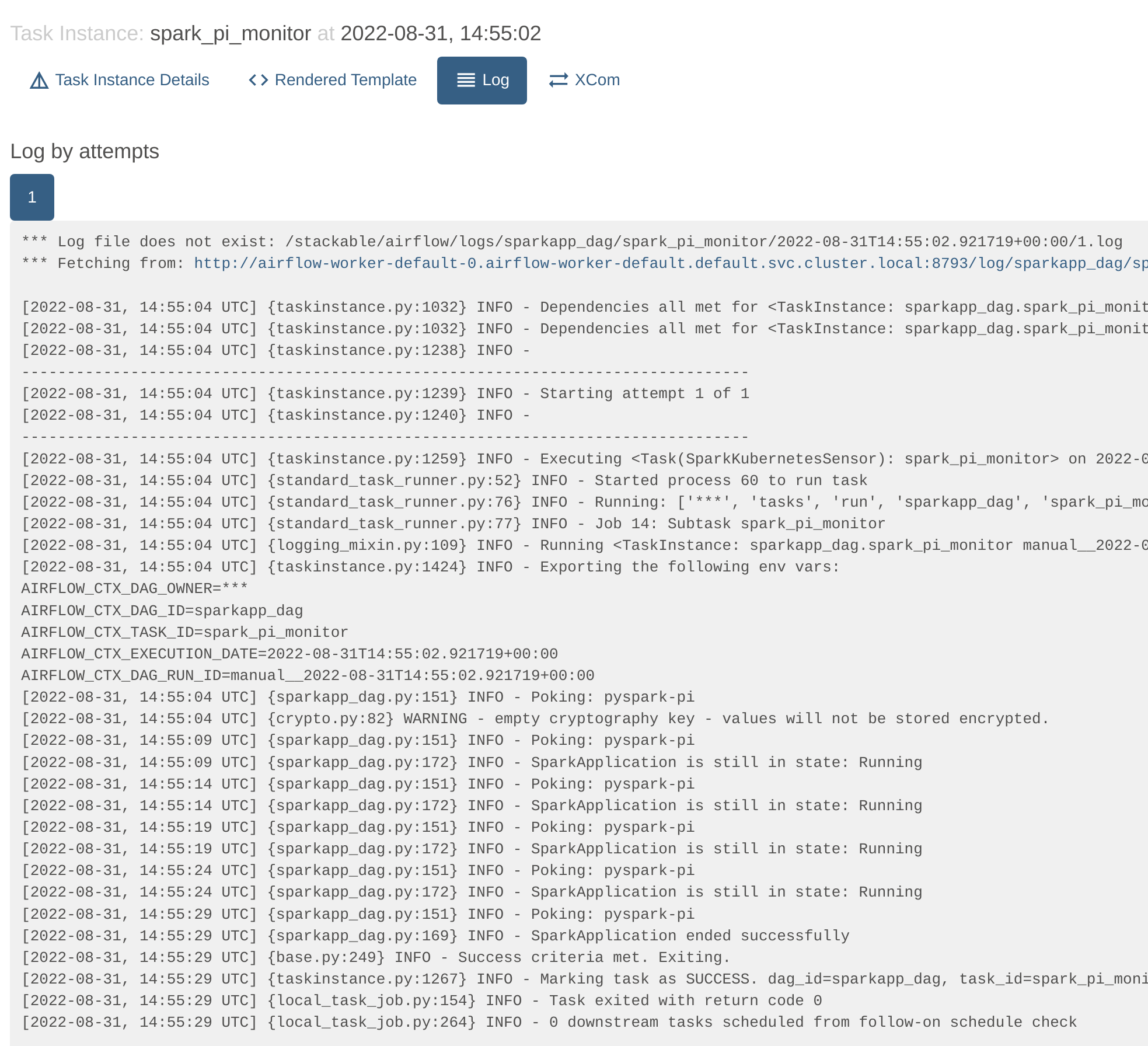
Clicking on the "spark_pi_monitor" task and selecting the logs shows that the status of the job has been tracked by Airflow: