Job Dependencies
Overview
The Stackable Spark-on-Kubernetes operator enables users to run Apache Spark workloads in a Kubernetes cluster easily by eliminating the requirement of having a local Spark installation. For this purpose, Stackble provides ready made Docker images with recent versions of Apache Spark and Python - for PySpark jobs - that provide the basis for running those workloads. Users of the Stackable Spark-on-Kubernetes operator can run their workloads on any recent Kubernetes cluster by applying a SparkApplication custom resource in which the job code, job dependencies, input and output data locations can be specified. The Stackable operator translates the user’s SparkApplication manifest into a Kubernetes Job object and handles control to the Apache Spark scheduler for Kubernetes to construct the necessary driver and executor Pods.
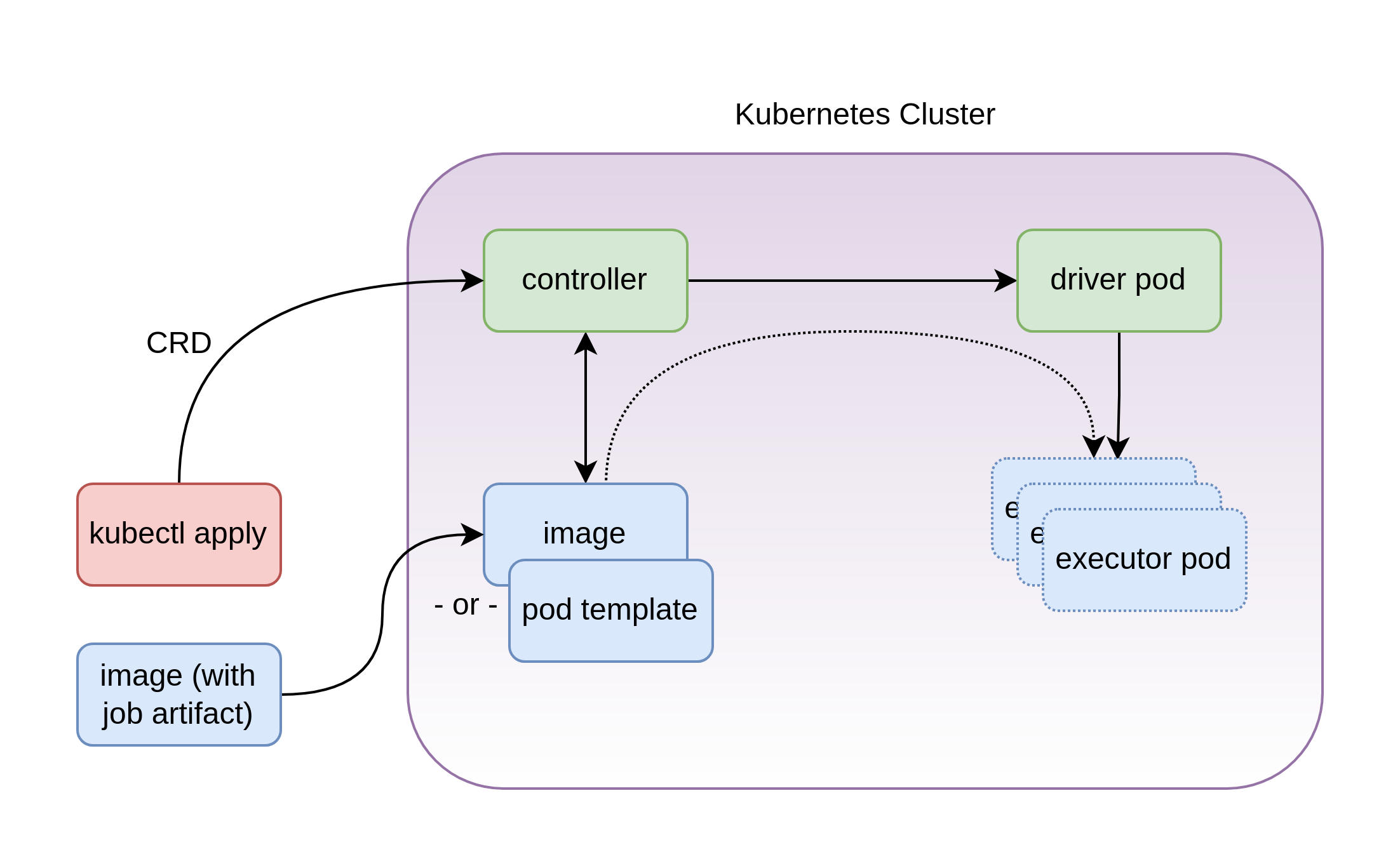
When the job is finished, the Pods are terminated and the Kubernetes Job is completed.
The base images provided by Stackable contain only the minimum of components to run Spark workloads. This is done mostly for performance and compatibility reasons. Many Spark workloads build on top of third party libraries and frameworks and thus depend on additional packages that are not included in the Stackable images. This guide explains how users can provision their Spark jobs with additional dependencies.
Dependency provisioning
There are multiple ways to submit Apache Spark jobs with external dependencies. Each has its own advantages and disadvantages and the choice of one over the other depends on existing technical and managerial constraints.
To provision job dependencies in their workloads, users have to construct their SparkApplication with one of the following dependency specifications:
-
Hardened or encapsulated job images
-
Dependency volumes
-
Spark native package coordinates and Python requirements
The following table provides a high level overview of the relevant aspects of each method.
| Dependency specification | Job image size | Reproduciblity | Dev-op cost |
|---|---|---|---|
Encapsulated job images |
Large |
Guaranteed |
Medium to High |
Dependency volumes |
Small |
Guaranteed |
Small to Medium |
Spark and Python packages |
Small |
Not guranteed |
Small |
Hardened or encapsulated job images
With this method, users submit a SparkApplication for which the sparkImage refers to a Docker image containing Apache Spark itself, the job code and dependencies required by the job. It is recommended the users base their image on one of the Stackable images to ensure compatibility with the Stackable operator.
Since all packages required to run the Spark job are bundled in the image, the size of this image tends to get very large while at the same time guaranteeing reproducibility between submissions.
Example:
---
apiVersion: spark.stackable.tech/v1alpha1
kind: SparkApplication
metadata:
name: spark-pi
spec:
version: "1.0"
sparkImage: docker.stackable.tech/stackable/spark-k8s:3.3.0-stackable0.3.0 (1)
mode: cluster
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: /stackable/spark/examples/jars/spark-examples_2.12-3.3.0.jar (2)
executor:
instances: 3| 1 | Name of the encapsulated image. |
| 2 | Name of the Spark job to run. |
Dependency volumes
With this method, the user provisions the job dependencies from a PersistentVolume as shown in this example:
---
apiVersion: spark.stackable.tech/v1alpha1
kind: SparkApplication
metadata:
name: example-sparkapp-pvc
namespace: default
spec:
version: "1.0"
sparkImage: docker.stackable.tech/stackable/spark-k8s:3.3.0-stackable0.3.0
mode: cluster
mainApplicationFile: s3a://stackable-spark-k8s-jars/jobs/ny-tlc-report-1.0-SNAPSHOT.jar (1)
mainClass: org.example.App (2)
args:
- "'s3a://nyc-tlc/trip data/yellow_tripdata_2021-07.csv'"
sparkConf: (3)
"spark.hadoop.fs.s3a.aws.credentials.provider": "org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider"
"spark.driver.extraClassPath": "/dependencies/jars/*"
"spark.executor.extraClassPath": "/dependencies/jars/*"
volumes:
- name: job-deps (4)
persistentVolumeClaim:
claimName: pvc-ksv
driver:
volumeMounts:
- name: job-deps
mountPath: /dependencies (5)
executor:
instances: 3
volumeMounts:
- name: job-deps
mountPath: /dependencies (5)| 1 | Job artifact located on S3. |
| 2 | Job main class |
| 3 | Spark dependencies: the credentials provider (the user knows what is relevant here) plus dependencies needed to access external resources (in this case, in s3, accessed without credentials) |
| 4 | the name of the volume mount backed by a PersistentVolumeClaim that must be pre-existing |
| 5 | the path on the volume mount: this is referenced in the sparkConf section where the extra class path is defined for the driver and executors |
| The Spark operator has no control over the contents of the dependency volume. It is the responsibility of the user to make sure all required dependencies are installed in the correct versions. |
A PersistentVolumeClaim and the associated PersistentVolume can be defined like this:
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-ksv (1)
spec:
storageClassName: standard
accessModes:
- ReadWriteOnce
capacity:
storage: 2Gi
hostPath:
path: /some-host-location
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-ksv (2)
spec:
volumeName: pv-ksv (1)
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: batch/v1
kind: Job
metadata:
name: aws-deps
spec:
template:
spec:
restartPolicy: Never
volumes:
- name: job-deps (3)
persistentVolumeClaim:
claimName: pvc-ksv (2)
containers:
- name: aws-deps
volumeMounts:
- name: job-deps (4)
mountPath: /stackable/spark/dependencies| 1 | Reference to a PersistentVolume, defining some cluster-reachable storage |
| 2 | The name of the PersistentVolumeClaim that references the PV |
| 3 | Defines a Volume backed by the PVC, local to the Custom Resource |
| 4 | Defines the VolumeMount that is used by the Custom Resource |
Spark native package coordinates and Python requirements
The last and most flexible way to provision dependencies is to use the built-in spark-submit support for Maven package coordinates.
These can be specified by adding the following section to the SparkApplication manifest file:
spec:
deps:
repositories:
- https://repository.example.com/prod
packages:
- com.example:some-package:1.0.0
excludePackages:
- com.example:other-packageThese directly translate to the spark-submit parameters --packages, --exclude-packages, and --repositories.
When submitting PySpark jobs, users can specify pip requirements that are installed before the driver and executor pods are created.
Here is an example:
---
apiVersion: spark.stackable.tech/v1alpha1
kind: SparkApplication
metadata:
name: example-sparkapp-external-dependencies
namespace: default
spec:
version: "1.0"
sparkImage: docker.stackable.tech/stackable/pyspark-k8s:3.3.0-stackable0.3.0
mode: cluster
mainApplicationFile: s3a://stackable-spark-k8s-jars/jobs/ny_tlc_report.py (1)
args:
- "--input 's3a://nyc-tlc/trip data/yellow_tripdata_2021-07.csv'" (2)
deps:
requirements:
- tabulate==0.8.9 (3)
sparkConf: (4)
"spark.hadoop.fs.s3a.aws.credentials.provider": "org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider"
"spark.driver.extraClassPath": "/dependencies/jars/*"
"spark.executor.extraClassPath": "/dependencies/jars/*"
volumes:
- name: job-deps (5)
persistentVolumeClaim:
claimName: pvc-ksv
driver:
volumeMounts:
- name: job-deps
mountPath: /dependencies (6)
executor:
instances: 3
volumeMounts:
- name: job-deps
mountPath: /dependencies (6)Note the section requirements. Also note that in this case, a sparkImage that bundles Python has to be provisioned.