Usage
Monitoring
The managed Airflow instances are automatically configured to export Prometheus metrics. See Monitoring for more details.
Log aggregation
The logs can be forwarded to a Vector log aggregator by providing a discovery ConfigMap for the aggregator and by enabling the log agent:
spec:
vectorAggregatorConfigMapName: vector-aggregator-discovery
webservers:
config:
logging:
enableVectorAgent: true
containers:
airflow:
loggers:
"flask_appbuilder":
level: WARN
workers:
config:
logging:
enableVectorAgent: true
containers:
airflow:
loggers:
"airflow.processor":
level: INFO
schedulers:
config:
logging:
enableVectorAgent: true
containers:
airflow:
loggers:
"airflow.processor_manager":
level: INFO
databaseInitialization:
logging:
enableVectorAgent: trueFurther information on how to configure logging, can be found in Logging.
Configuration & Environment Overrides
The cluster definition also supports overriding configuration properties and environment variables, either per role or per role group, where the more specific override (role group) has precedence over the less specific one (role).
| Overriding certain properties which are set by operator (such as the HTTP port) can interfere with the operator and can lead to problems. Additionally, for Airflow it is recommended that each component has the same configuration: not all components use each setting, but some things - such as external end-points - need to be consistent for things to work as expected. |
Configuration Properties
Airflow exposes an environment variable for every Airflow configuration setting, a list of which can be found in the Configuration Reference.
Although Kubernetes can override these settings in one of two ways (Configuration overrides, or Environment Variable overrides), the affect is the same and currently only the latter is implemented. This is described in the following section.
Environment Variables
These can be set - or overwritten - at either the role level:
webservers:
envOverrides:
AIRFLOW__WEBSERVER__AUTO_REFRESH_INTERVAL: "8"
roleGroups:
default:
replicas: 1Or per role group:
webservers:
roleGroups:
default:
envOverrides:
AIRFLOW__WEBSERVER__AUTO_REFRESH_INTERVAL: "8"
replicas: 1In both examples above we are replacing the default value of the UI DAG refresh (3s) with 8s. Note that all override property values must be strings.
Storage for data volumes
The Airflow Operator currently does not support using PersistentVolumeClaims for internal storage.
Resource Requests
Stackable operators handle resource requests in a sligtly different manner than Kubernetes. Resource requests are defined on role or group level. See Roles and role groups for details on these concepts. On a role level this means that e.g. all workers will use the same resource requests and limits. This can be further specified on role group level (which takes priority to the role level) to apply different resources.
This is an example on how to specify CPU and memory resources using the Stackable Custom Resources:
---
apiVersion: example.stackable.tech/v1alpha1
kind: ExampleCluster
metadata:
name: example
spec:
workers: # role-level
config:
resources:
cpu:
min: 300m
max: 600m
memory:
limit: 3Gi
roleGroups: # role-group-level
resources-from-role: # role-group 1
replicas: 1
resources-from-role-group: # role-group 2
replicas: 1
config:
resources:
cpu:
min: 400m
max: 800m
memory:
limit: 4GiIn this case, the role group resources-from-role will inherit the resources specified on the role level. Resulting in a maximum of 3Gi memory and 600m CPU resources.
The role group resources-from-role-group has maximum of 4Gi memory and 800m CPU resources (which overrides the role CPU resources).
| For Java products the actual used Heap memory is lower than the specified memory limit due to other processes in the Container requiring memory to run as well. Currently, 80% of the specified memory limits is passed to the JVM. |
For memory only a limit can be specified, which will be set as memory request and limit in the Container. This is to always guarantee a Container the full amount memory during Kubernetes scheduling.
If no resource requests are configured explicitely, the operator uses the following defaults:
workers:
roleGroups:
default:
config:
resources:
cpu:
min: '200m'
max: "4"
memory:
limit: '2Gi'Initializing the Airflow database
Airflow comes with a default embedded database (intended only for standalone mode): for cluster usage an external database is used such as PostgreSQL, described above. This database must be initialized with an airflow schema and the Admin user defined in the airflow credentials Secret. This is done the first time the cluster is created and can take a few moments.
Using Airflow
When the Airflow cluster is created and the database is initialized, Airflow can be opened in the browser.
The Airflow port which defaults to 8080 can be forwarded to the local host:
kubectl port-forward airflow-webserver-default-0 8080Then it can be opened in the browser with http://localhost:8080.
Enter the admin credentials from the Kubernetes secret:
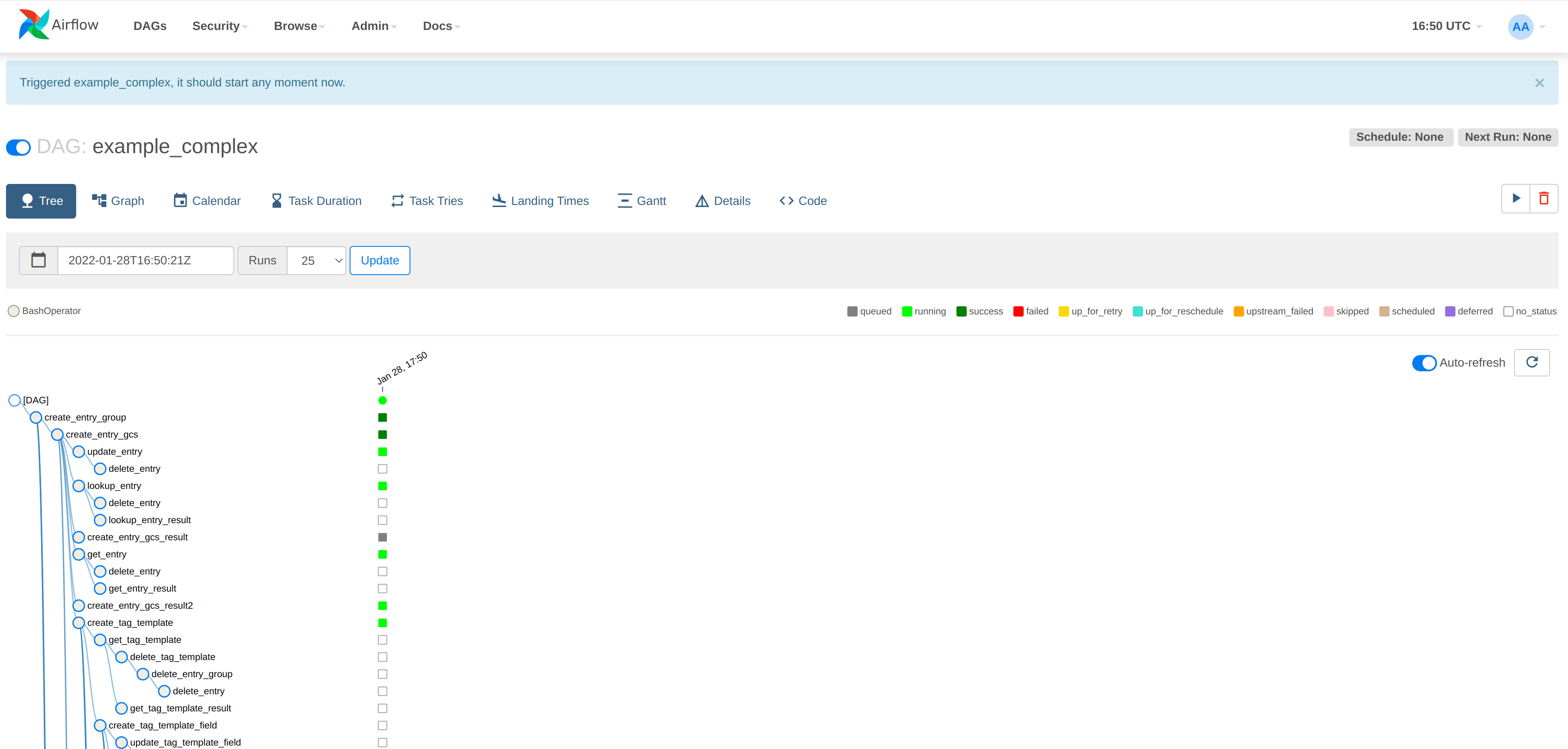
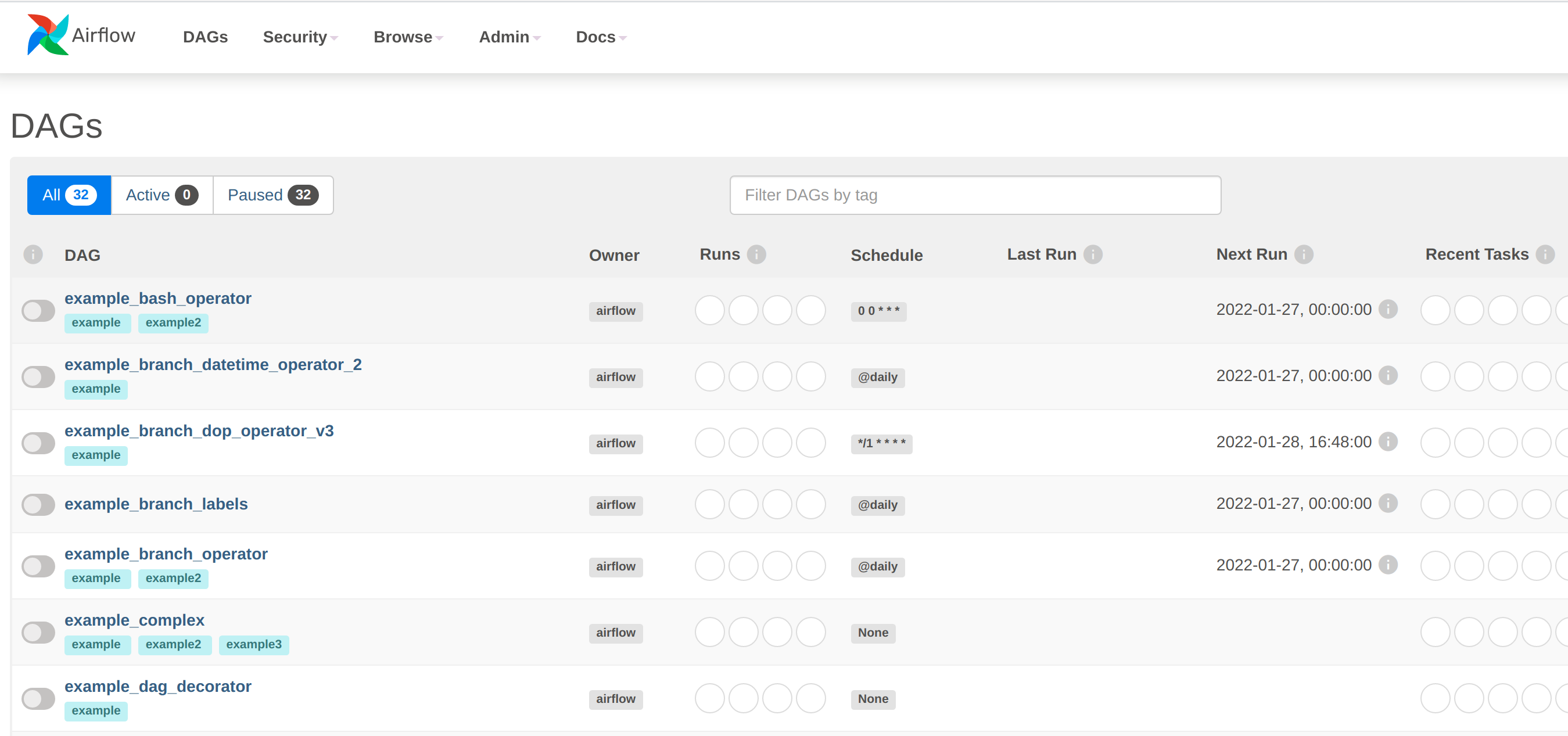
If the examples were loaded then some dashboards are already available:
Click on an example DAG and then invoke the job: if the scheduler is correctly set up then the job will run and the job tree will update automatically: