Applying Custom Resources
Airflow can be used to apply custom resources from within a cluster. An example of this could be a SparkApplication job that is to be triggered by Airflow. The steps below describe how this can be done.
Define an in-cluster Kubernetes connection
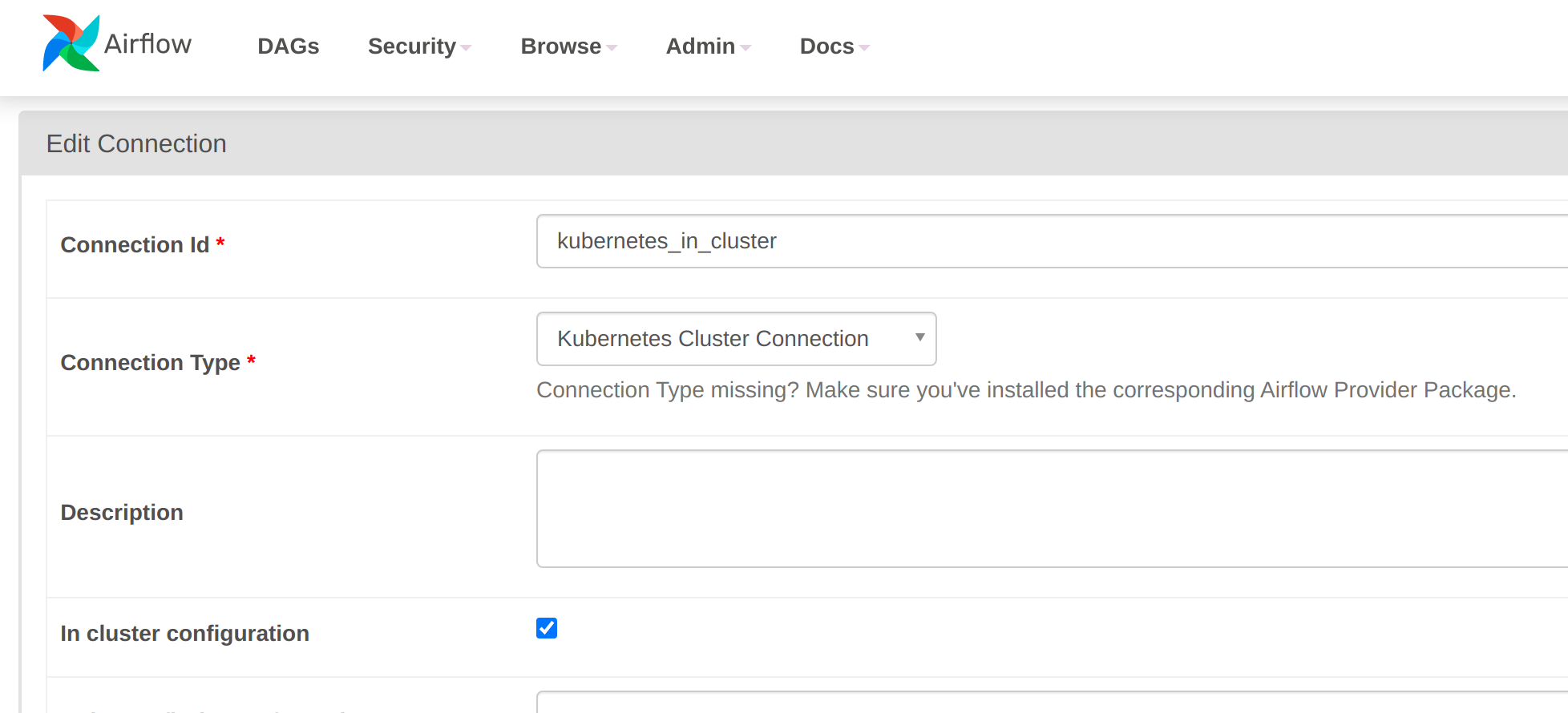
An in-cluster connection can either be created from within the Webserver UI (note that the "in cluster configuration" box is ticked):
Alternatively, the connection can be defined by an environment variable in URI format:
AIRFLOW_CONN_KUBERNETES_IN_CLUSTER: "kubernetes://?__extra__=%7B%22extra__kubernetes__in_cluster%22%3A+true%2C+%22extra__kubernetes__kube_config%22%3A+%22%22%2C+%22extra__kubernetes__kube_config_path%22%3A+%22%22%2C+%22extra__kubernetes__namespace%22%3A+%22%22%7D"This can be supplied directly in the custom resource for all roles (Airflow expects configuration to be common across components):
---
apiVersion: airflow.stackable.tech/v1alpha1
kind: AirflowCluster
metadata:
name: airflow
spec:
image:
productVersion: 2.6.1
stackableVersion: 0.0.0-dev
clusterConfig:
executor: CeleryExecutor
loadExamples: false
exposeConfig: false
credentialsSecret: simple-airflow-credentials
webservers:
roleGroups:
default:
envOverrides:
AIRFLOW_CONN_KUBERNETES_IN_CLUSTER: "kubernetes://?__extra__=%7B%22extra__kubernetes__in_cluster%22%3A+true%2C+%22extra__kubernetes__kube_config%22%3A+%22%22%2C+%22extra__kubernetes__kube_config_path%22%3A+%22%22%2C+%22extra__kubernetes__namespace%22%3A+%22%22%7D"
replicas: 1
workers:
roleGroups:
default:
envOverrides:
AIRFLOW_CONN_KUBERNETES_IN_CLUSTER: "kubernetes://?__extra__=%7B%22extra__kubernetes__in_cluster%22%3A+true%2C+%22extra__kubernetes__kube_config%22%3A+%22%22%2C+%22extra__kubernetes__kube_config_path%22%3A+%22%22%2C+%22extra__kubernetes__namespace%22%3A+%22%22%7D"
replicas: 1
schedulers:
roleGroups:
default:
envOverrides:
AIRFLOW_CONN_KUBERNETES_IN_CLUSTER: "kubernetes://?__extra__=%7B%22extra__kubernetes__in_cluster%22%3A+true%2C+%22extra__kubernetes__kube_config%22%3A+%22%22%2C+%22extra__kubernetes__kube_config_path%22%3A+%22%22%2C+%22extra__kubernetes__namespace%22%3A+%22%22%7D"
replicas: 1Define a cluster role for Airflow to create SparkApplication resources
Airflow cannot create or access SparkApplication resources by default - a cluster role is required for this:
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: airflow-spark-clusterrole
rules:
- apiGroups:
- spark.stackable.tech
resources:
- sparkapplications
verbs:
- create
- getand a corresponding cluster role binding:
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: airflow-spark-clusterrole-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: airflow-spark-clusterrole
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:serviceaccountsDAG code
Now for the DAG itself. The job to be started is a simple Spark job that calculates the value of pi:
---
apiVersion: spark.stackable.tech/v1alpha1
kind: SparkApplication
metadata:
name: pyspark-pi
namespace: default
spec:
version: "1.0"
sparkImage: docker.stackable.tech/stackable/pyspark-k8s:3.3.0-stackable0.0.0-dev
mode: cluster
mainApplicationFile: local:///stackable/spark/examples/src/main/python/pi.py
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
executor:
cores: 1
instances: 3
memory: "512m"This will called from within a DAG by using the connection that was defined earlier. It will be wrapped by the KubernetesHook that the Airflow Kubernetes provider makes available [here.](https://github.com/apache/airflow/blob/main/airflow/providers/cncf/kubernetes/operators/spark_kubernetes.py) There are two classes that are used to:
-
start the job
-
monitor the status of the job
These are written in-line in the python code below, though this is just to make it clear how the code is used (the classes SparkKubernetesOperator and SparkKubernetesSensor will be used for all custom resources and thus are best defined as separate python files that the DAG would reference).
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
"""Example DAG demonstrating how to apply a Kubernetes Resource from Airflow running in-cluster"""
from datetime import datetime, timedelta
from airflow import DAG
from typing import TYPE_CHECKING, Optional, Sequence, Dict
from kubernetes import client
from airflow.exceptions import AirflowException
from airflow.sensors.base import BaseSensorOperator
from airflow.models import BaseOperator
from airflow.providers.cncf.kubernetes.hooks.kubernetes import KubernetesHook
if TYPE_CHECKING:
from airflow.utils.context import Context
class SparkKubernetesOperator(BaseOperator): (1)
"""
Creates a SparkApplication resource in kubernetes:
:param application_file: Defines a 'SparkApplication' custom resource as either a
path to a '.yaml' file, '.json' file, YAML string or JSON string.
:param namespace: kubernetes namespace for the SparkApplication
:param kubernetes_conn_id: The :ref:`kubernetes connection id <howto/connection:kubernetes>`
for the Kubernetes cluster.
:param api_group: SparkApplication API group
:param api_version: SparkApplication API version
"""
template_fields: Sequence[str] = ('application_file', 'namespace')
template_ext: Sequence[str] = ('.yaml', '.yml', '.json')
ui_color = '#f4a460'
def __init__(
self,
*,
application_file: str,
namespace: Optional[str] = None,
kubernetes_conn_id: str = 'kubernetes_in_cluster', (2)
api_group: str = 'spark.stackable.tech',
api_version: str = 'v1alpha1',
**kwargs,
) -> None:
super().__init__(**kwargs)
self.application_file = application_file
self.namespace = namespace
self.kubernetes_conn_id = kubernetes_conn_id
self.api_group = api_group
self.api_version = api_version
self.plural = "sparkapplications"
def execute(self, context: 'Context'):
hook = KubernetesHook(conn_id=self.kubernetes_conn_id)
self.log.info("Creating SparkApplication...")
response = hook.create_custom_object(
group=self.api_group,
version=self.api_version,
plural=self.plural,
body=self.application_file,
namespace=self.namespace,
)
return response
class SparkKubernetesSensor(BaseSensorOperator): (3)
"""
Monitors a SparkApplication resource in kubernetes:
:param application_name: SparkApplication resource name
:param namespace: the kubernetes namespace where the SparkApplication reside in
:param kubernetes_conn_id: The :ref:`kubernetes connection<howto/connection:kubernetes>`
to Kubernetes cluster.
:param attach_log: determines whether logs for driver pod should be appended to the sensor log
:param api_group: SparkApplication API group
:param api_version: SparkApplication API version
"""
template_fields = ("application_name", "namespace")
FAILURE_STATES = ("Failed", "Unknown")
SUCCESS_STATES = ("Succeeded")
def __init__(
self,
*,
application_name: str,
attach_log: bool = False,
namespace: Optional[str] = None,
kubernetes_conn_id: str = 'kubernetes_in_cluster', (2)
api_group: str = 'spark.stackable.tech',
api_version: str = 'v1alpha1',
poke_interval: float = 60,
**kwargs,
) -> None:
super().__init__(**kwargs)
self.application_name = application_name
self.attach_log = attach_log
self.namespace = namespace
self.kubernetes_conn_id = kubernetes_conn_id
self.hook = KubernetesHook(conn_id=self.kubernetes_conn_id)
self.api_group = api_group
self.api_version = api_version
self.poke_interval = poke_interval
def _log_driver(self, application_state: str, response: dict) -> None:
if not self.attach_log:
return
status_info = response["status"]
if "driverInfo" not in status_info:
return
driver_info = status_info["driverInfo"]
if "podName" not in driver_info:
return
driver_pod_name = driver_info["podName"]
namespace = response["metadata"]["namespace"]
log_method = self.log.error if application_state in self.FAILURE_STATES else self.log.info
try:
log = ""
for line in self.hook.get_pod_logs(driver_pod_name, namespace=namespace):
log += line.decode()
log_method(log)
except client.rest.ApiException as e:
self.log.warning(
"Could not read logs for pod %s. It may have been disposed.\n"
"Make sure timeToLiveSeconds is set on your SparkApplication spec.\n"
"underlying exception: %s",
driver_pod_name,
e,
)
def poke(self, context: Dict) -> bool:
self.log.info("Poking: %s", self.application_name)
response = self.hook.get_custom_object(
group=self.api_group,
version=self.api_version,
plural="sparkapplications",
name=self.application_name,
namespace=self.namespace,
)
try:
application_state = response["status"]["phase"]
except KeyError:
self.log.debug(f"SparkApplication status could not be established: {response}")
return False
if self.attach_log and application_state in self.FAILURE_STATES + self.SUCCESS_STATES:
self._log_driver(application_state, response)
if application_state in self.FAILURE_STATES:
raise AirflowException(f"SparkApplication failed with state: {application_state}")
elif application_state in self.SUCCESS_STATES:
self.log.info("SparkApplication ended successfully")
return True
else:
self.log.info("SparkApplication is still in state: %s", application_state)
return False
with DAG( (4)
dag_id='sparkapp_dag',
schedule_interval='0 0 * * *',
start_date=datetime(2021, 1, 1),
catchup=False,
dagrun_timeout=timedelta(minutes=60),
tags=['example'],
params={"example_key": "example_value"},
) as dag:
t1 = SparkKubernetesOperator( (5)
task_id='spark_pi_submit',
namespace="default",
application_file="pyspark-pi.yaml",
do_xcom_push=True,
dag=dag,
)
t2 = SparkKubernetesSensor( (6)
task_id='spark_pi_monitor',
namespace="default",
application_name="{{ task_instance.xcom_pull(task_ids='spark_pi_submit')['metadata']['name'] }}",
poke_interval=5,
dag=dag,
)
t1 >> t2 (7)| 1 | the wrapper class used for calling the job via KubernetesHook |
| 2 | the connection that created for in-cluster usage |
| 3 | the wrapper class used for monitoring the job via KubernetesHook |
| 4 | the start of the DAG code |
| 5 | the initial task to invoke the job |
| 6 | the subsequent task to monitor the job |
| 7 | the jobs are chained together in the correct order |
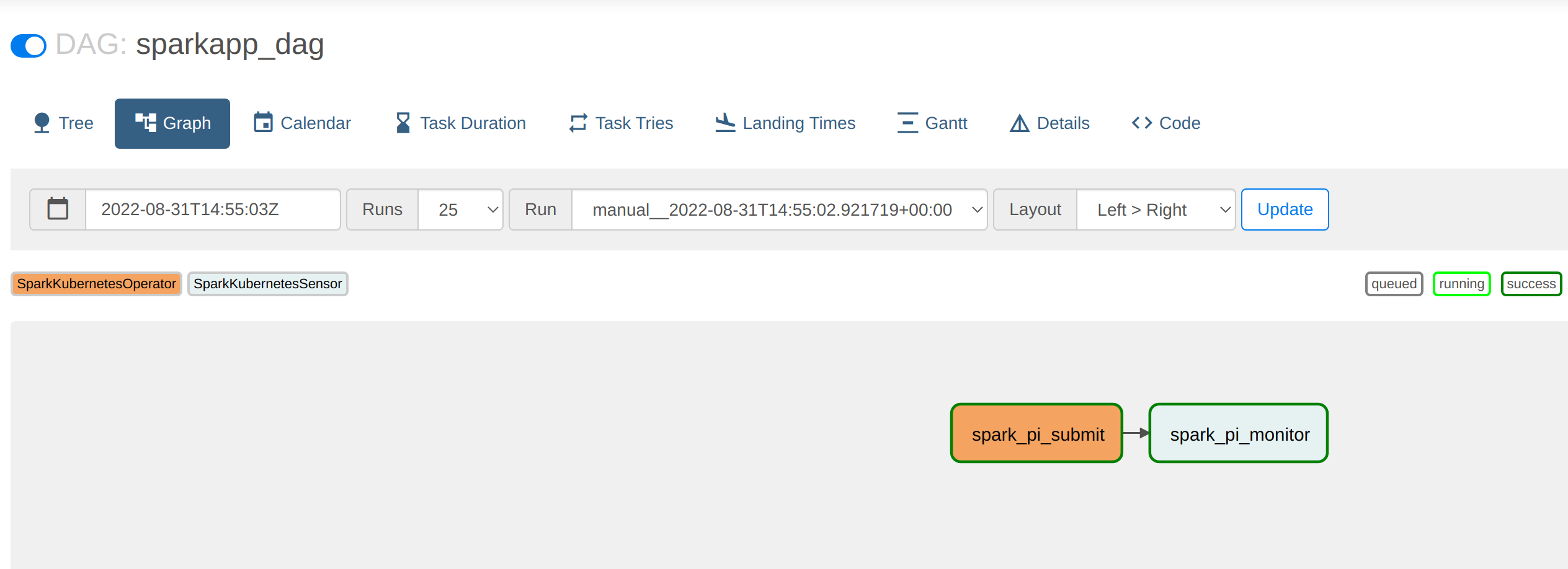
Once this DAG is mounted in the DAG folder it can be called and its progress viewed from within the Webserver UI:
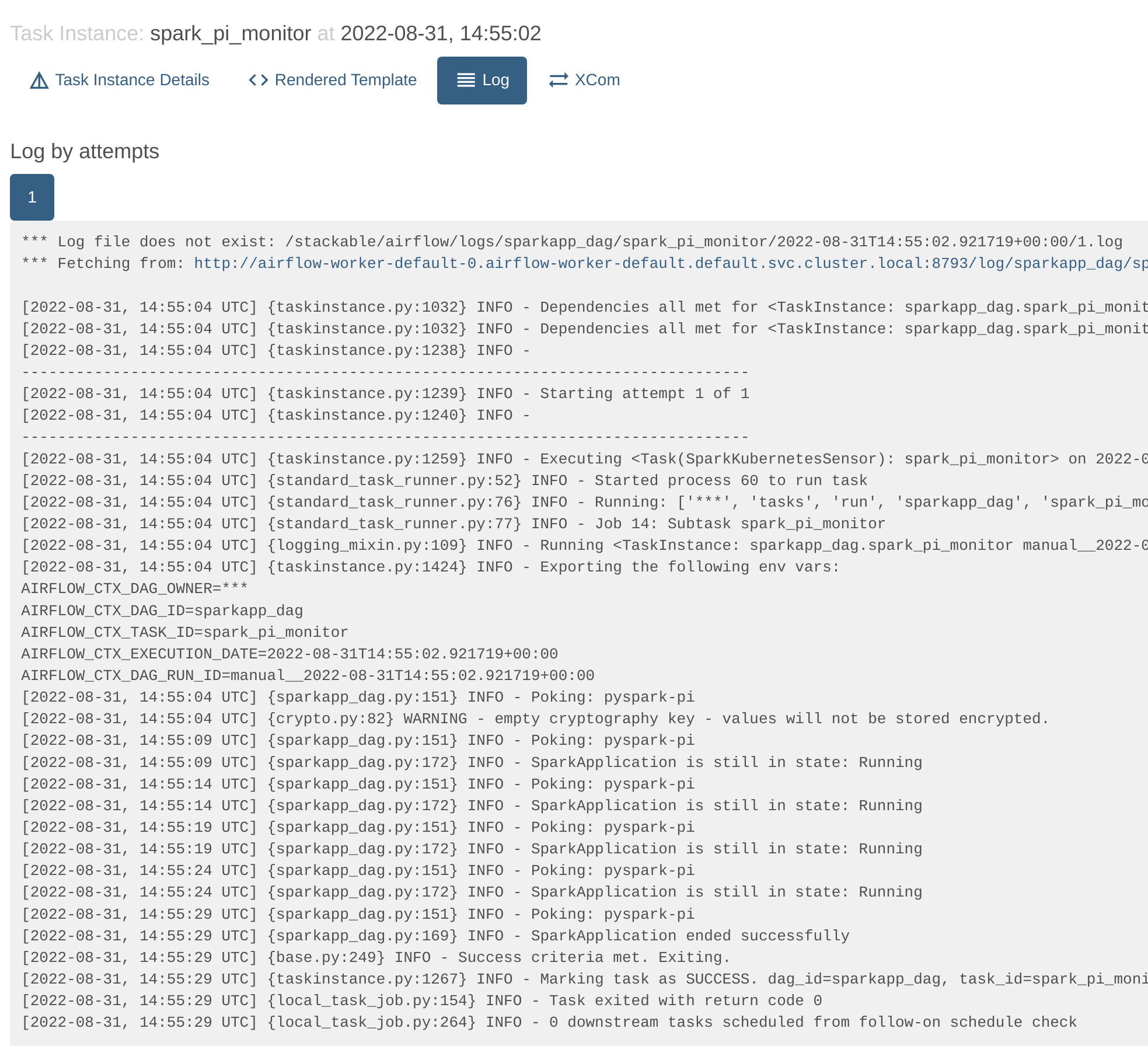
Clicking on the "spark_pi_monitor" task and selecting the logs shows that the status of the job has been tracked by Airflow: