ADR007: Decide if Kubernetes Components Are to be Reused for Stackable
-
Status: draft
-
Deciders:
-
Florian Waibel
-
Lars Francke
-
Lukas Menzel
-
Oliver Hessel
-
Sönke Liebau
-
-
Date: 27.08.2020
Context and Problem Statement
The Stackable project will need at least two components in order to orchestrate the software that gets deployed. These components are the orchestrator and the agents that manage bare-metal (or virtual) servers.
During previous design discussions it became quite clear that a lot of the issues that we need to for these components are very similar to issues that Kubernetes faced in the past - and solved already. Some examples of this are:
-
Agents need to register with the orchestrator in a secure way
-
The orchestrator needs a mechanism for operators to subscribe to data
In theory, Kubernetes components are extensible enough that it should allow us to implement our components in a way that we can deploy them on top of an existing Kubernetes. This would save us some work, as we’d for example not have to reimplement the registration process for agents.
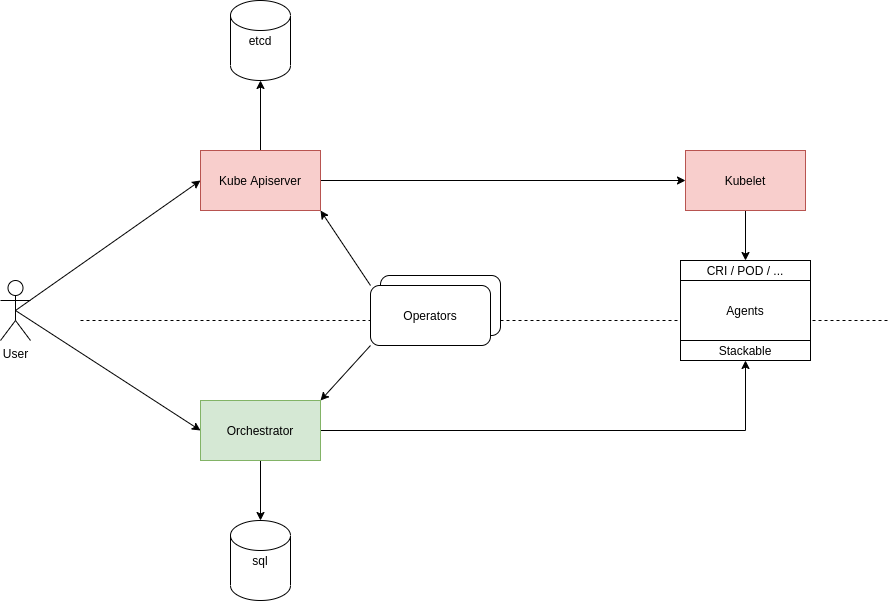
The image shows the two main options that we have identified during deliberations so far:
-
shaded in red is the option of reusing Kubernetes components (please refer to Reuse kube-apiserver and kubelet for more details)
-
shaded in green is the option of writing our own components (please refer to Start from Scratch for more details)
Decision Drivers
-
Avoiding too tight coupling with Kubernetes development & community
-
Deployment effort for potential customers
-
Development effort
Decision Outcome
Chosen option: "Reuse only kube-apiserver", because the amount of work to get a sufficient version of our orchestrator up and running is currently holding us back from achieving results that provide actual benefits to potential customers.
While this increases our dependency on the Kubernetes project and potentially increases the deployment effort for customers a bit it has significant upsides as well. The main benefit is the fact that this will give as a battle-tested orchestrator right now, which we can use for our development. The Kubernetes api is very complex and reimplementing the pieces of the api-server that we need turned out to be more effort than expected.
In the interest of reaching a MVP as early as possible we decided to push the final decision down the road a bit.
This option is no decision for Kubernetes for good, but rather a decision for the first iteration of the product. By taking this step we are forcing ourselves to remain compatible with Kubernetes and keep the option open of implementing a limited version of the api-server later.
Pros and Cons of the Options
Reuse kube-apiserver and kubelet
Stackable needs to deploy a server-client architecture where the decentralized agent receives commands from the central server to execute these. In order to create an infrastructure like this, there are some functions that need to be in place. Some examples for these functions are:
-
Deploy TLS keys and certificates to agents
-
Register agents with orchestrator
-
Monitor agents for liveness
-
Communication between components
-
Tagging and selection of executing nodes
-
…
Most of these functions would be considered boiler-plate and are not exclusive to our intended use-case. Kubernetes has implemented a lot of this functionality already and we could try to reuse this by deploying our components on top of an existing Kubernetes infrastructure.
The general idea would not be to fork Kubernetes and just reuse the code for our purposes, but rather to deploy the orchestrator as for example an operator in a vanilla Kubernetes cluster and deploying CRDs for our necessary data structures. This way the operator could subscribe to our resources and publish the necessary downstream structures that Stackable operators would then listen to.
Thinking the concept a bit further we might even get away without an orchestrator as most functionality is taken over by the Kube apiserver already.
-
Good, because we do not need to reimplement existing functionality
-
Bad, because we have to strictly adhere to Kubernetes structures for everything we do
-
Bad, because we would need to marry our release cycles to the very short cycles of Kubernetes
-
Bad, because for customers without an existing Kubernetes we would need to somehow provision a Kubernetes cluster
-
Bad, because for some customers Kubernetes is not a technology that they want to invest in
-
Bad, because we have to keep a very close eye on Kubernetes development to ensure we remain compatible with everything they do
Reuse only kube-apiserver
Since we aim to be api compatible with Kubernetes, we could use the api-server from Kubernetes as our central communications hub instead of a custom built orchestrator. As all components we plan to develop need to interface with this central server anyway this is an easy way of ensuring that we stay api-compatible every step of the way.
Additionally this does not need a final decision, depending on how many Kubernetes features we end up using, it might still be an option at a later point in time to create our own apiserver in Rust und roll that out to customers who are not using Kubernetes.
-
Good, because ops and dev-persons could keep using their existing Kubernetes tools and know-how
-
Good, because we save the initial effort of implementing a api-compatible apiserver
-
Good, because it is a reversible decision that allows us to gather speed at this time
-
Bad, because it may tempt us to end up using more and more kube-apiserver functionality which would make it harder and harder to write our own implementation later
-
Bad, because this forces us to use etcd as storage backend, we were originally planning to rather go with a sql database
Start from Scratch
We implement the orchestrator and the agent from scratch, instead of reusing any Kubernetes code. By doing this we gain the flexibility of designing our data structures and APIs as we see fit as well as decoupling us from Kubernetes release cycles.
For this option, it is worth noting, that we will not simply ignore Kubernetes in everything we do, but still pay close attention not to break compatibility with Kubernetes. This is to ensure that a later move towards Kubernetes does not become overly complex.
-
Good, because this does not complicate deployments for customers without existing Kubernetes
-
Good, because we don’t force customers to use Kubernetes
-
Good, because we don’t need to adhere to the short Kubernetes release cycles
-
Good, because we can design our solution independent of Kubernetes APIs and data structures
-
Good, because we do not need to pay too close attention to the Kubernetes community with regards to breaking changes (for us, not for them)
-
Bad, because we duplicate some effort that has already been done by the Kubernetes community
-
Bad, because we potentially need to implement converters, if our structures differ from Kubernetes