ADR016: Representation of S3 Buckets in CRDs
-
Status: accepted
-
Deciders:
-
Felix Hennig
-
Sebastian Bernauer
-
Siegfried Weber
-
Sönke Liebau
-
Teo Klestrup Röijezon
-
-
Date: 29.04.2022
Context and Problem Statement
Currently we do not have a common schema of how we refer to S3 buckets that are used by the managed product. For example Trino, Druid and Hive all require/support specifying one or more S3 buckets to access, for some of the tools these buckets can reside on separate S3 endpoints (AWS, MinIO, Ceph, …).
We want to define a shared set of CRDs which can be used to specify these connections in an easy and composable fashion and works the same for all products across the Stackable Data Platform.
Decision Drivers
-
Must allow using multiple S3 endpoints in the same environment
-
Must support buckets with generated names that are not known up front (like with Rook’s object bucket claim pattern)
-
Must allow specifying just an S3 backend without a bucket (for example Trino and Druid need this)
-
Should be easy to use for the end-user and not require scripting or similar things to take care of repetitively specifying the same S3 endpoint for multiple buckets (or comparable issues)
-
Should favor native K8s mechanisms like ownership and reconciliation notifications over custom logic
-
Must not put extra effort on the user in order to be easier to implement
Considered Options
-
Option 1: Isolating S3 endpoint details in an S3Connection object and credentials in the S3Bucket
-
Option 2: Inlining S3 endpoint details in the S3Bucket object
-
Option 3: Inlining bucket name and credentials in the product configuration
-
Option 4: Isolating S3 endpoint details and credentials in an S3Connection object
-
Option 5: Merge of options 1, 3 & 4
-
Option 6: Generate inlined S3Connection objects from templates with a dedicated controller
-
Option 7: Use the ConfigMap format that has been defined by Rook for use with its object bucket claim method
Decision Outcome
Chosen option: "Option 5" with caveats, because it allows us to start with a simple implementation that works for now, but can be gradually expanded to include more complex cases over time.
We will in step 1 implement only the inlined version of the S3Bucket object like this:
---
apiVersion: v1
kind: S3Bucket
metadata:
name: my-bucket
data:
bucketName: my-bucket-123
secretClass: minio-credentials
s3Connection:
inline:
host: test-minio
port: 9000
tls:
verification:
server:
caCert:
secretClass: my-s3-caImplementing this gives us a working solution and buys time to evaluate options for implementing more complex functionality.
A required decision that was more or less orthogonal to the main decision documented in this ADR was to make all objects discussed in this ADR namespaced instead of cluster scoped, as this is in line with the overall approach of allowing namespace isolation for Stackable infrastructures.
We will spike the second half of option 5> as well as <<option6,option 6 and see which one has more potential and creates the least amount of implementation issues. A big part of this spike will be considering the needed watches on S3 objects which a operator would need to maintain.
The decision on how to proceed will be documented in a separate ADR later on.
Special mention should be given to Option 7 here, the main reason for deciding against this option was because we felt it wouldn’t make sense to use this standard and then extend it with non-standard settings that we need for our purposes - effectively diverting from the standard again.
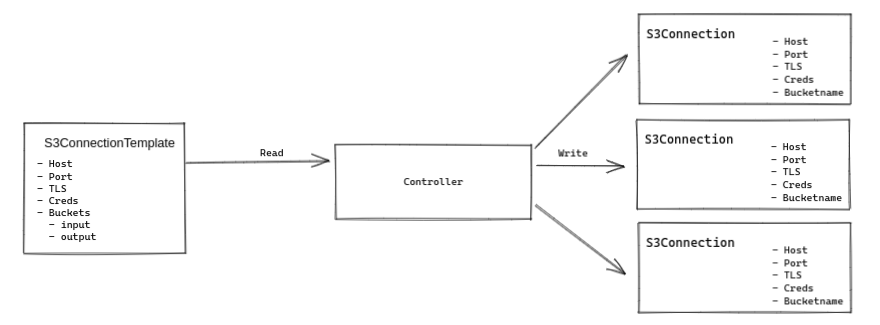
We decided to instead support object bucket claims by writing a controller that watches for these configmaps and converts them into our chosen notation for referring to buckets. The image below shows the control flow at a high level, a more detailed design will be done at a later time and is out of scope for this document.
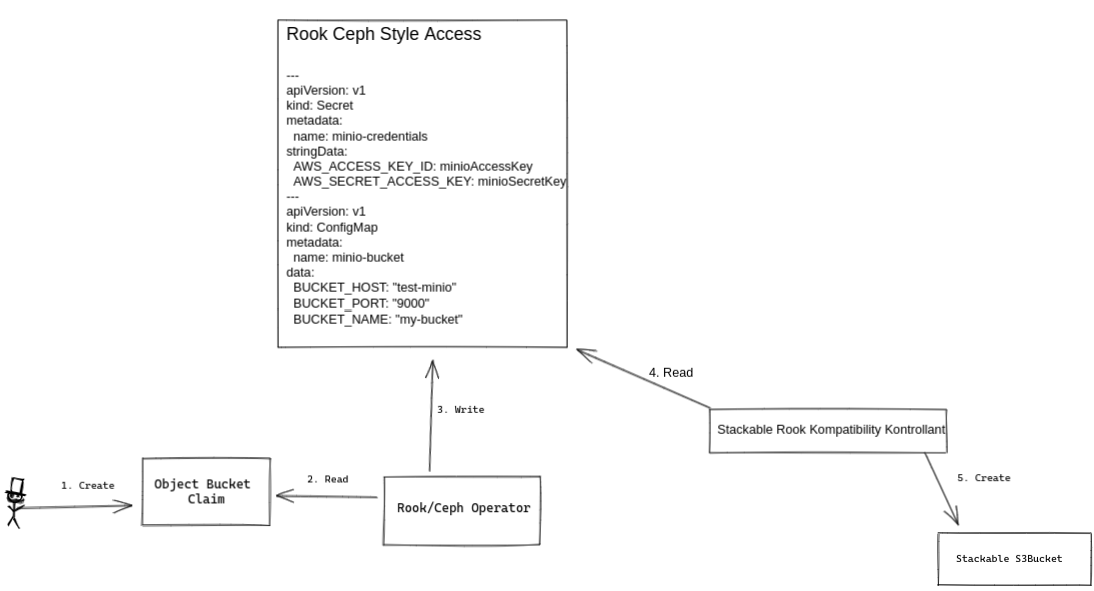
Pros and Cons of the Options
Option 1: Isolating S3 endpoint details in an S3Connection object and credentials in the S3Bucket
This option splits the definition of an S3 bucket over two objects with at least the following fields defined:
-
S3Bucket
-
Bucket name
-
Credentials
-
-
S3Connection
-
Endpoint
-
TLS Config
-
The purpose of this split is to make the S3Connection reusable over multiple buckets. For a user in an environment that only uses one S3 endpoint this would allow specifying the endpoint and port only once and then whenever buckets need to be configured only the bucket name and credentials need to be specified.
This would for example allow defining different S3Connection objects in the test and dev environment, allowing the S3Bucket objects to be deployed to both environments unchanged, but still addressing different backends.
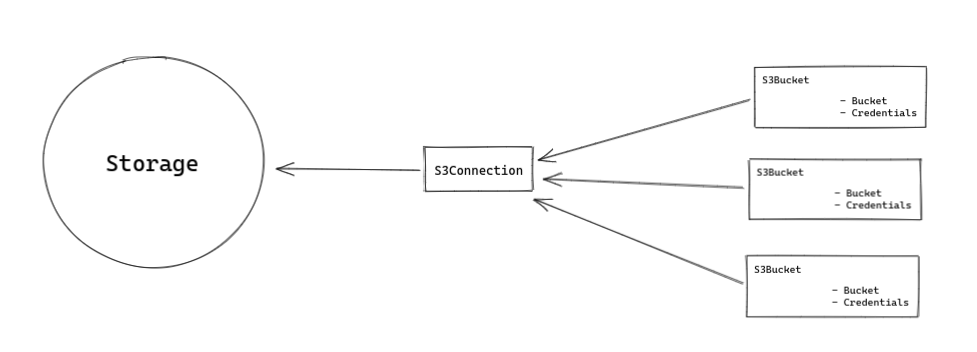
Example
---
apiVersion: v1
kind: S3Connection
metadata:
name: my-minio
data:
host: test-minio
port: 9000
tls:
verification:
server:
caCert:
secretClass: my-s3-ca
---
apiVersion: v1
kind: S3Bucket
metadata:
name: my-bucket
data:
bucketName: my-bucket-123
s3Connection: my-minio
secretClass: minio-credentials-
Good, because it reduces duplication of information
-
Good, because it allows explicitly referring to an S3 backend from product that need this (Trino, Druid)
-
Bad, because it adds a level of indirection that controllers need pay attention to for reconciliation triggers
Option 2: Inlining S3 endpoint details in the S3Bucket object
This option inlines the S3 backend details into the S3Bucket object:
-
S3Bucket
-
Bucket name
-
Credentials
-
Endpoint
-
TLS Config
-
This makes code in the operator as well as debugging issues easier as all needed information are kept in the same object. At the same time this introduces a high amount of repetition for the user, as the same backend needs to be specified for every bucket object (and changed should anything in the backend ever change).
This option makes reconciliation triggers simpler for the operator, but doesn’t fully eliminate the need for custom watches, as the same S3Connection object could be referenced from multiple product CRDs and we cannot make use of ownership to trigger reconciliation cleanly.
Example
---
apiVersion: v1
kind: S3Connection
metadata:
name: my-minio
data:
host: test-minio
port: 9000
bucketName: my-bucket-123
secretClass: minio-credentials
tls:
verification:
server:
caCert:
secretClass: my-s3-ca
[example | description | pointer to more information | …] <!-- optional -→
-
Good, because simpler for the user to understand
-
Good, because simpler for the operator to use
-
Bad, because puts the burden of repetition on the user (probably tooling will need to be created around this)
-
Bad, because sacrifices flexibility while not completely eliminating the need for custom watches in the controller
Option 3: Inlining bucket name and credentials in the product configuration
This is similar to Option 1 in that it separates the definition of S3 endpoint details from the bucket name and credentials.
However this option foregoes the extra S3Bucket object in favor of directly referencing the S3Endpoint object from the product configuration CRD. The bucket name and credentials would also be specified in the product config CRD.
Example:
---
apiVersion: v1
kind: S3Connection
metadata:
name: my-minio
data:
host: test-minio
port: 9000
tls:
verification:
server:
caCert:
secretClass: my-s3-ca
---
apiVersion: v1
kind: ProductCluster
metadata:
name: my-product
spec:
version: "1.2.3"
s3config:
bucketName: my-bucket
s3Connection: my-minio
secretClass: minio-credentials
-
Good, because it simplifies the overall structure
-
Bad, because it doesn’t allow reusing a defined s3 bucket for a different cluster definition
-
Bad, because it does not support using buckets with generated names, as the name would need to be known up front for the cluster definition
Option 4: Isolating S3 endpoint details and credentials in an S3Connection object
Option 4 can be considered a variant of Option 1 where the location of the credential used to access S3 is moved from the S3Bucket object to the S3Connection object.
Example:
---
apiVersion: v1
kind: S3Connection
metadata:
name: my-minio
data:
host: test-minio
port: 9000
secretClass: minio-credentials
tls:
verification:
server:
caCert:
secretClass: my-s3-ca
---
apiVersion: v1
kind: S3Bucket
metadata:
name: my-bucket
data:
bucketName: my-bucket-123
s3Connection: my-minio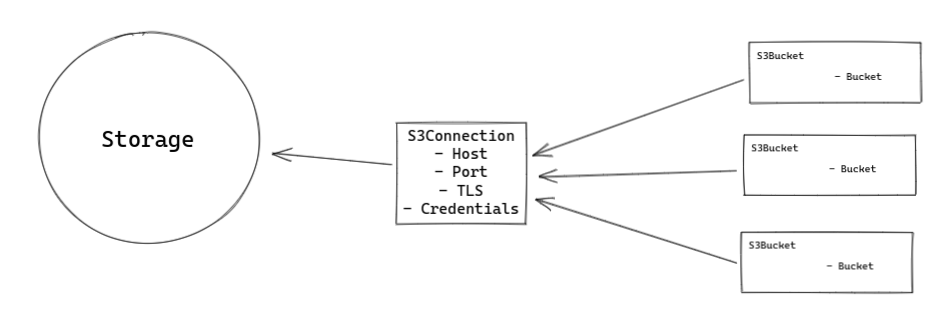
-
Good, because it allows for an easy way to specify an S3 backend without specifying a bucket for products like Trino or Druid
-
Bad, because it would result in a lot of S3Connection objects being created due to the inability to access buckets on the same S3 backend with different credentials
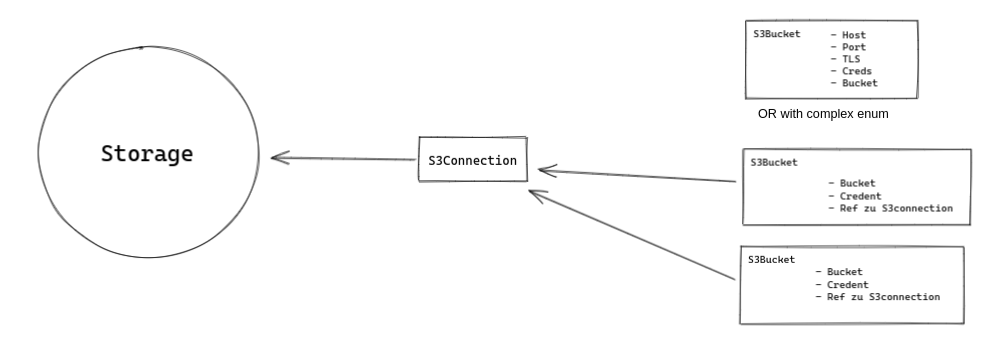
Option 5: Merge of options 1, 3 & 4
This option attempts to introduce flexibility in the data model to capitalize on the benefits of multiple options mentioned so far.
By making the S3 backend configuration a complex enum in the S3Bucket object it is possible to allow one out of multiple possible way to refer to an S3 backend:
-
Directly specify the needed value in the S3Bucket object
-
Refer to an S3Connection object
Additionally both objects will provide the option of specifying credentials to use for authentication. The principle for resolving this is that credentials specified on a bucket object would override credentials specified on an S3Connection object. If both objects do not provide credentials an anonymous connection would be attempted.
Example - Inlined endpoint:
---
apiVersion: v1
kind: S3Bucket
metadata:
name: my-bucket
data:
bucketName: my-bucket-123
s3Connection:
inline:
host: test-minio
port: 9000
secretClass: minio-credentials
tls:
verification:
server:
caCert:
secretClass: my-s3-caExample - Reference to endpoint, credentials from S3Connection object:
---
apiVersion: v1
kind: S3Connection
metadata:
name: my-minio
data:
host: test-minio
port: 9000
secretClass: minio-credentials
tls:
verification:
server:
caCert:
secretClass: my-s3-ca
---
apiVersion: v1
kind: S3Bucket
metadata:
name: my-bucket
data:
bucketName: my-bucket-123
s3Connection:
reference:
s3endpoint: my-minioExample - Reference to endpoint, credentials override:
---
apiVersion: v1
kind: S3Connection
metadata:
name: my-minio
data:
host: test-minio
port: 9000
secretClass: minio-credentials
tls:
verification:
server:
caCert:
secretClass: my-s3-ca
---
apiVersion: v1
kind: S3Bucket
metadata:
name: my-bucket
data:
bucketName: my-bucket-123
secretClass: my-personal-minio-credentials
s3Connection:
reference:
s3endpoint: my-minioFor making this easier to use from the operators it could be helpful to provide a method in the operator framework that resolves a referenced variant of an S3Bucket into an inlined version of the same S3Bucket, so that operators would only need to implement one variant.
The code listing below gives an idea of how this might look from very high up.
struct S3Connection {
host: Option<String>,
port: Option<String>,
//...
credentials: Option<S3Credentials>,
}
struct S3Bucket {
connection: Option<S3ConnectionReference>,
bucket_name: Option<String>,
}
enum S3ConnectionReference {
inline {
host: Option<String>,
port: Option<String>,
},
external {
referencename: Option<String>, // refers to the name of an S3Connection object
}
}
struct S3Credentials {
//...
}
pub fn resolve_s3_bucket(bucket: &S3Bucket) -> Result<Bucket> {
if let Some(conn) = bucket.connection {
Ok(match conn {
S3ConnectionReference::inline { conn } => conn ,
S3ConnectionReference::external { conn } => {
// Create s3 bucket with inlined connection and return
conn.inline_connection()
}
})
}
Ok(())
}
-
Good, because it gives a lot of flexibility in defining S3 buckets, it pretty much has all the benefits of options 1, 3 & 4
-
Good, because we can start implementing only the inline configuration so that the operators only have to watch a single object (similar to option 2). Later on the reference mechanism can be added without a breaking change (as an addition to the complex enum).
-
Bad, because setting up all necessary watches in the operator to ensure objects are reconciled as needed will become extremely complex
Option 6: Generate inlined S3Connection objects from templates with a dedicated controller
This option solves the issue of unnecessarily repeating S3 endpoint details in every S3Bucket object by adding a controller that generates S3Buckets from templates that allow defining S3Connection templates in bulk.
By offering a default way of generating multiple S3Buckets from a single object we try to preempt users from creating tooling of their own for generating these types of objects.
-
Good, because it makes watches easy-ish to set up in the operators (identical to option 2)
-
Bad, because it requires creating a template object per set of credentials that are to be used for accessing the S3 endpoint
Option 7: Use the ConfigMap format that has been defined by Rook for use with its object bucket claim method
There is an existing format for specifying object buckets in ConfigMaps that has been defined by RedHat (or maybe just documented and defined by someone else).
Adhering to this format would have the benefit of automatically being compatible with any external system that uses this standard. This option can be considered roughly equivalent to Option2, as the content of the ConfigMap matches what is specified in the S3Connection object for that option.
-
Good, because it is an established standard that would make our operators compatible with this standard
-
Bad, because it does not give us the flexibility of adding content that we need and while staying fully compatible
apiVersion: v1 kind: ConfigMap metadata: name: my-bucket data: BUCKET_HOST: 10.0.171.35 BUCKET_NAME: test21obc-933348a6-e267-4f82-82f1-e59bf4fe3bb4 BUCKET_PORT: "31242" BUCKET_REGION: "" BUCKET_SUBREGION: ""