Writing to Iceberg tables
Apache Iceberg is a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Spark, Trino, Flink, Presto, Hive and Impala to safely work with the same tables, at the same time.
NiFi supports a PutIceberg processor to add rows to an existing Iceberg table starting from version 1.19.0.
As of NiFi version 1.23.1 only PutIceberg is supported, you need to create and compact your tables with other tools such as Trino or Spark (both included in the SDP).
The following example shows an example NiFi setup using the Iceberg integration.
apiVersion: nifi.stackable.tech/v1alpha1
kind: NifiCluster
metadata:
name: nifi
spec:
clusterConfig:
# ...
extraVolumes:
# Will be mounted at /stackable/userdata/nifi-hive-s3-config/
- name: nifi-hive-s3-config
secret:
secretName: nifi-hive-s3-config
---
apiVersion: v1
kind: Secret
metadata:
name: nifi-hive-s3-config
stringData:
core-site.xml: |
<configuration>
<property>
<name>fs.s3a.aws.credentials.provider</name>
<value>org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>http://minio:9000</value>
</property>
<property>
<name>fs.s3a.access.key</name>
<value>xxx</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>xxx</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
<property>
<name>fs.s3a.connection.ssl.enabled</name>
<value>false</value>
<description>Enables or disables SSL connections to S3.</description>
</property>
</configuration>Please fill in the correct endpoint, access key and secret key for your S3 store, this is a classic Hadoop config file.
Use e.g. Trino to create a table for Nifi to write into using something like
CREATE SCHEMA IF NOT EXISTS lakehouse.demo WITH (location = 's3a://lakehouse/demo/');
CREATE TABLE IF NOT EXISTS lakehouse.demo.test (
test varchar
);In NiFi you need to create a HiveCatalogService first which allows you to access the Hive Metastore storing the Iceberg metadata.
Set Hive Metastore URI to something like thrift://hive-iceberg.default.svc.cluster.local:9083,
Default Warehouse Location to s3a://lakehouse
and Hadoop Configuration Resources to /stackable/userdata/nifi-hive-s3-config/core-site.xml.
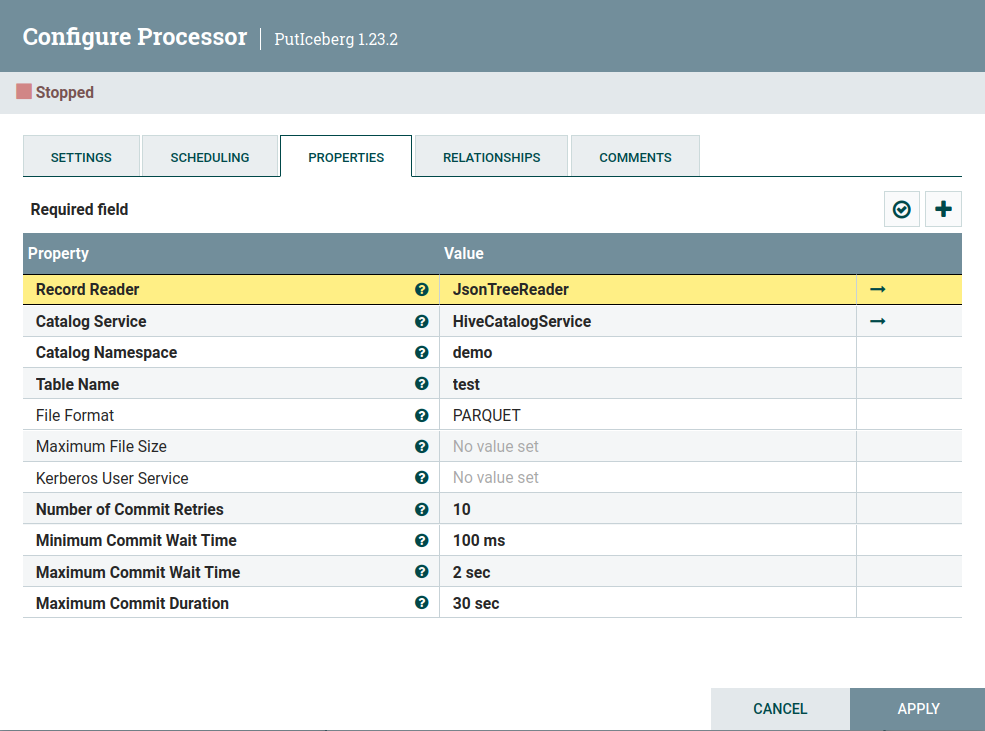
Afterwards you can create the PutIceberg processor and configure the HiveCatalogService.
Also set Catalog Namespace to your schema name and the Table Name.
For the File Format it is recommened to use PARQUET or ORC rather than AVRO for performance reasons, but you can leave it empty or choose your desired format.
You should end up with the following PutIceberg processor: